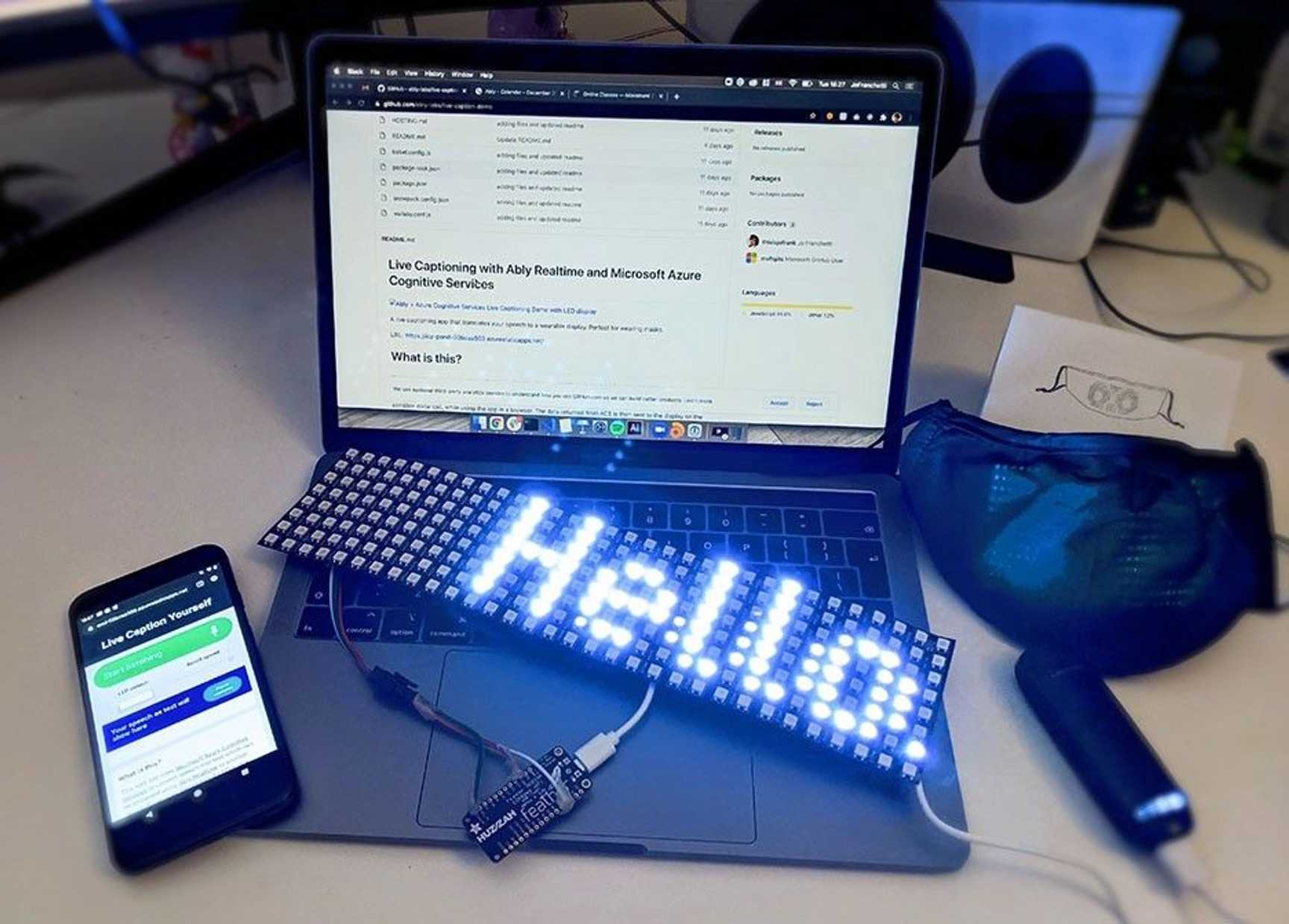
Live captioning of speech into text has so many useful applications and Azure Cognitive Services makes it fast and easy to build captioning into your applications. Used together with Ably Realtime, it is possible to make wearable devices which can display what you’re saying, in real time. Wearable live captions!
This article will explain how to use Azure Speech and Ably Realtime and will go through building a web app that will take data from your microphone and turn it into readable text.
Check out this video to see the demo in action:
Why would we want this?
I’ll admit to a personal desire to see more products like this on the market. The reason is my mother. She has been steadily losing her hearing over the last few years and relies heavily on lip reading and clear pronunciation. Two things which are denied to her when the people talking to her are wearing masks. Of course I also want to keep her safe, so I will always encourage everyone to wear a mask, but there must be ways that technology can make her, and many others, life easier. One of the frustrations with assistive technologies on phones is that they require her to be looking at her phone, rather than at the speaker, which can lead to her being treated differently, often poorly, by whoever is speaking to her.
Inspiration hit when I saw an LED wearable mask on sale (at Cyberdog, of all places).

It is a face mask with a wearable LED display inside. The display is incredibly small, flexible, breathable and has very low power consumption. What if I could send text to the display from my phone’s microphone? It could update the mask display to show what I am saying!
So began my journey to build a wearable live captioning demo.
What is the wearable live captioning demo?
The demo consists of a web app, which is used to capture microphone data and send it to Azure Cognitive Services. When it receives text back, the web app can display it to the user. It also contains a virtual representation of the hardware display to visualise what the hardware display will be showing. The app uses the Ably Javascript SDK along with their MQTT broker to send messages from the app to the wearable hardware.
The wearable part is a 32 by 8 display of neopixels (very small LEDs) connected to an Adafruit Feather Huzzah (a small, wifi enabled microprocessor) which is powered by a rechargeable USB battery.

How Does it work?
The web app is built with HTML, CSS and JS, it will run on your phone or your computer and just requires an internet connection and a microphone.
You can see and clone the code for the entire project on github, it is open source, and I’d be delighted if you used it to create your own wearable tech projects, especially if they can help make someone’s day better! Instructions on how to set up the app and its various dependencies are in there too.
Using the microphone
The getUserMedia() API has been in browsers for a while. It allows us to prompt the user for permission to use their microphone and or camera and, once allowed, get a stream of data from their media devices. This app uses just the audio, so it will only prompt for microphone permissions.
Processing the data stream with Azure Cognitive Services Speech
This app uses the Cognitive Services Speech service, which allows us to transcribe audible speech into readable, searchable text.
When a user clicks the “Start Listening” button on the app UI, a function called streamSpeechFromBrowser is called. This uses the Azure fromDefaultMicrophoneInput along with the fromAuthorisationToken function to authenticate with Azure and initialise a SpeechRecognizer. This is what will perform the speech recognition on the data coming from the mic. It will return an object which contains the text of what has been said.
Because the phone now has the transcription, and our microcontroller is connected to our LED display, the app needs to send the transcription to the hardware, in a format that it can understand so the code running on the hardware can convert that text into lights.
Using MQTT to send the data
To communicate between the web app and the microprocessor, a messaging protocol is required. MQTT is a lightweight publish/subscribe protocol, designed specifically for IoT devices and optimised for high latency or unreliable networks. This is perfect for this particular project where the wearer might be on a 3g connection.
In order to use MQTT, a broker is required, this is a service which is responsible for dispatching messages between the sender (or client) and the rightful receivers. The web app is the client, in this case, and the receiver is the microcontroller. This project uses the Ably MQTT broker, which comes for free with the Ably Javascript SDK. The web app can send messages using the Ably SDK and they will be automatically sent out using MQTT too.

Processing text commands
The microprocessor on the Adafruit Feather Huzzah is very small and therefore has limited processing power and memory, which means that the code that runs on it needs to be as efficient as possible. It is therefore necessary to avoid doing any complicated text parsing, string splitting or other similarly memory intensive tasks on the microprocessor. Parsing and splitting strings is especially costly, and involves larger buffers than would be ideal.
While at a glance, this may seem like premature performance optimisation, if all of the memory on the board is used parsing the messages as human readable strings, it decreases the amount of memory available to buffer incoming messages. To solve this problem, a binary message format is used to talk to the hardware. The browser app creates a specially coded message to send text strings to the device.
Where most systems would probably use JSON to serialize messages with properties, this app uses a binary format where the order and content of bytes as they are received is relevant to the hardware. For example, sending a command to scroll text across the display involves the browser sending a message that looks like this:
const textMessage = {
value: "My line of text",
mode: 1,
scrollSpeedMs: 25,
color: { r: 255, g: 255, b: 255 }
}
But rather than serializing this message to JSON, and sending it as text, it is packed down into a binary message that looks like this, byte by byte:
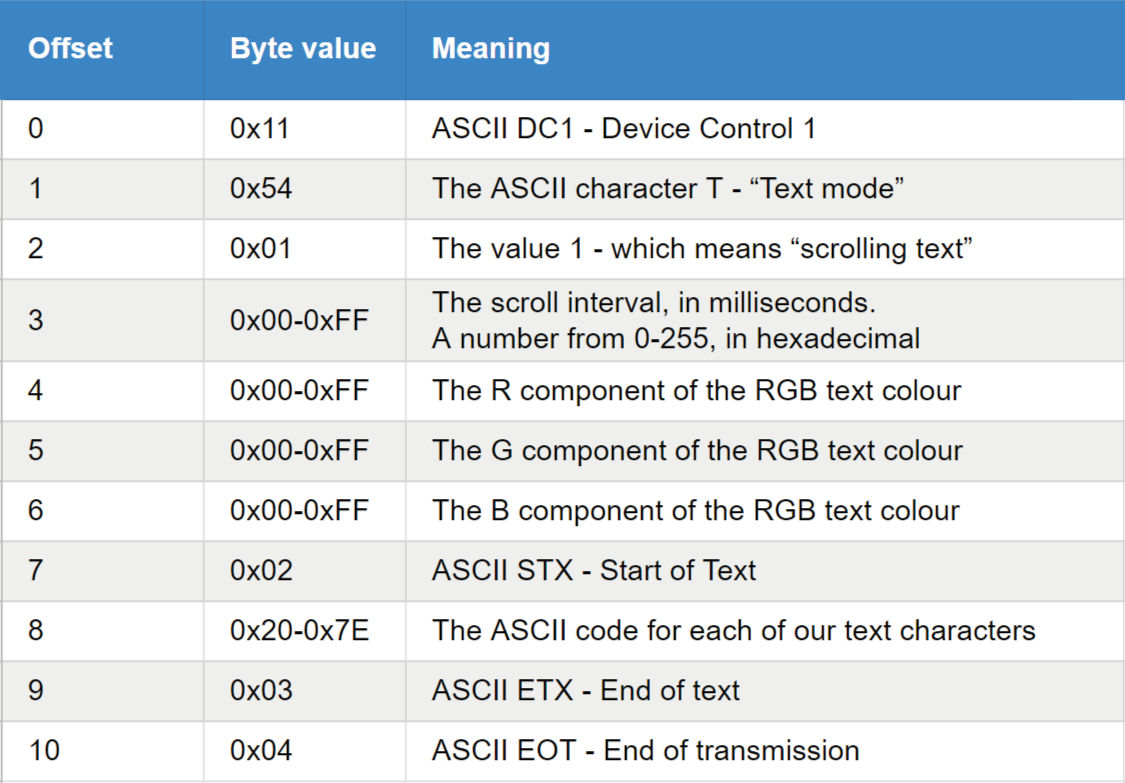
These messages are sent as raw bytes — the control codes in the ASCII standard are used to provide some header information in the messages.
Because the message is a raw byte stream, it is not necessary to parse the message on the hardware, it can just loop over the message bytes, and run different processes depending on the byte being looped over at the time. This takes all of the complexity of parsing text away from the microprocessor, and moves it into the TypeScript code in the web app, where it is easier to debug and test.
In the table above, the byte at offset 8 would represent a single character, but the parser on the hardware is looking out for the STX and ETX start and end of text markers. What this means is that any number of ASCII characters can be added in the space between them to form a full sentence in the message.
Displaying the results
Since the transcription from Azure Cognitive Services arrives as text, it is trivially simple to display this text to the user in a containing element within the app UI.
The microcontroller needs a way to convert the messages it receives as ASCII characters, into a format which can be shown on an 8 pixel high resolution matrix (it will support displays with a higher resolution, but not lower).
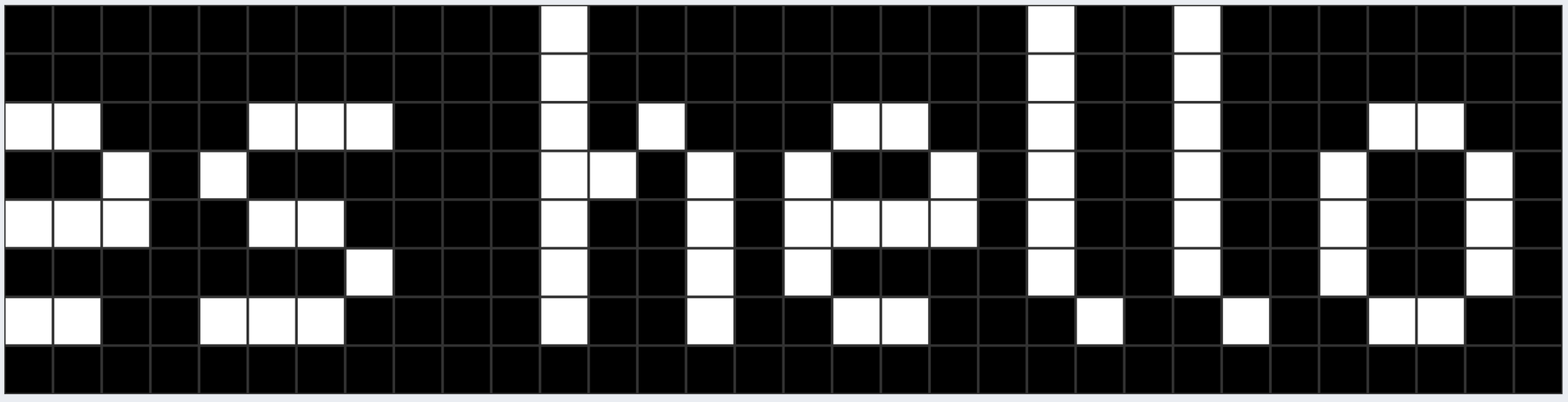
Creating a pixel “font”
The first thing to do was design some “pixel font” style alphanumeric characters and symbols


Which could be converted to an array of binary values. Let’s take, for example, the letter n. Which, represented visually, would look like this:
which as an array of binary values (where black = 1 and white = 0) would be:
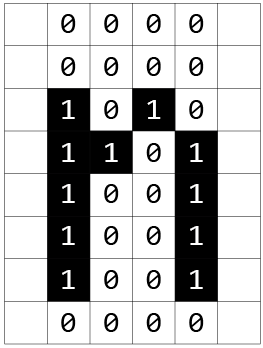
Or, as an array of binary values: [0,0,0,0,0,0,0,0,1,0,1,0,1,1,0,1,1,0,0,1,1,0,0,1,1,0,0,1,0,0,0,0]
The app uses a JavaScript image manipulation program called jimp to create this conversion from a png to one very long array containing all of the characters. The array also requires a list of indexes, which will point to the starting position of each letter and its width (you’ll notice from the graphic above, that the letters and symbols differ in width). These two byte arrays are small enough to be embedded on the microcontroller.
With the “font” arrays embedded on the device, it is possible to write code in C/C++ (the language that the microprocessor uses) to show the letters on the display. This means that instead of computing all of the individual pixel positions in the browser app, and sending them one by one, the microcontroller will handle the translation.
Hardware differences
LED displays, like the one used in this project are made up of addressable RGB LEDs. “Addressable” means that each LED on the display has its own address number, the first LED on the strip is LED 0, the second LED 1, and so on as they move along the matrix.
There is an open source Arduino library, written to interact with these LEDS, called AdaFruit NeoPixel which makes it simple to set the colour value of individual pixels with a pixel address (or ID) and a colour value, set in RGB (red, green blue).
Unfortunately, addressing the LEDs in the matrix isn’t quite as simple as I’d originally hoped. There are many different ways of wiring up an LED matrix, and every manufacturer seems to have a different preference!
Some common wiring patterns look like this:
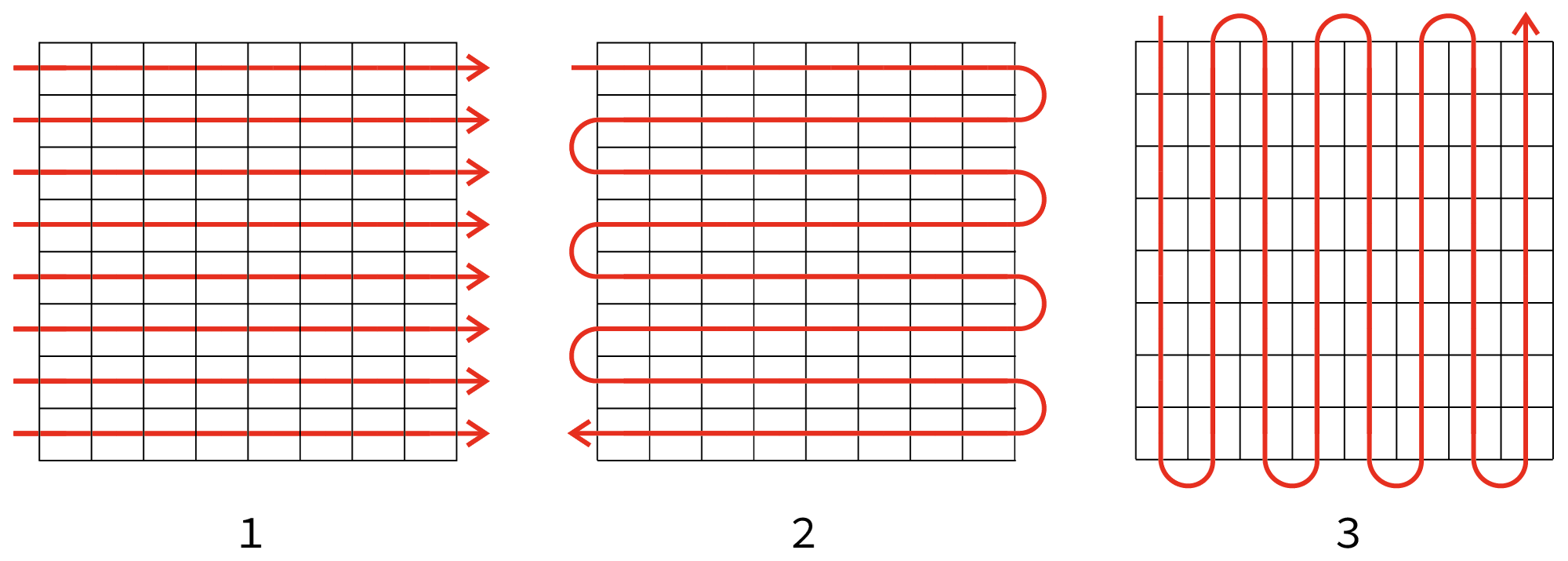
- Reading order — with pixel IDs incrementing from left to right.
- Snaking horizontally — Pixels increment from left to right, but then reverse on the way back.
- Snaking vertically — Pixels increment up and down the matrix.
Not only that, but the displays sometimes have connectors at both ends, which means that the numbering could go from left to right, or right to left, depending on which connector is used. These differences are mostly made to accommodate physical constraints, snaking the wires uses a lot less wiring than bringing the line back to the start of each row.
This variety of wiring patterns meant that the code running on the board needed to be able to translate from (x,y) coordinates into the appropriate pixel ID, so that developers working with this code will be able to use it with the display they own. This is done by ensuring that all of the operations in the JavaScript SDK library refer to pixel locations in (x,y) coordinates rather than pixel IDs. Once these coordinates are sent to the hardware, it will translate the coordinates into the correct pixel ID, based on hardware configuration code running on the board.
The microcontroller code has a single Configuration file included in the project that contains the display configuration, along with configuration for WiFi and MQTT settings:
//Display config
const int display_gpio_pin = 4;
const int display_width = 32;
const int display_height = 8;
const index_mode display_connector_location = index_mode::TOP_LEFT;
const carriage_return_mode line_wrap = carriage_return_mode::SNAKED_VERTICALLY;
const neoPixelType neopixel_type = NEO_GRB + NEO_KHZ800;
You can see here that every device needs to be told the GPIO (General Purpose IO) pin the display is connected to, the dimensions of the display, and the index_mode and carriage_return_mode settings that capture the possible difference between displays.
This means that the code will be able to drive cheap displays bought from different manufacturers, without spending time changing the code.
Turning the pixel font into scrolling text
With the microcontroller software now able to set pixels using any kind of display, and with the “font” arrays stored as variables in the Arduino C++ code, the missing piece is to write message handlers that process incoming binary messages, look up the “font” data for each letter in the message, and push the appropriate pixels to the display.
First let’s cover how static text can be written to the display -
When a message to display static text is received, the code loops through each text character present in the message and looks up that character in the embedded font. The font data that gets returned from the font is an array of bytes, with a single byte for every pixel to be set on the display, prefixed by the width of the character in pixels.
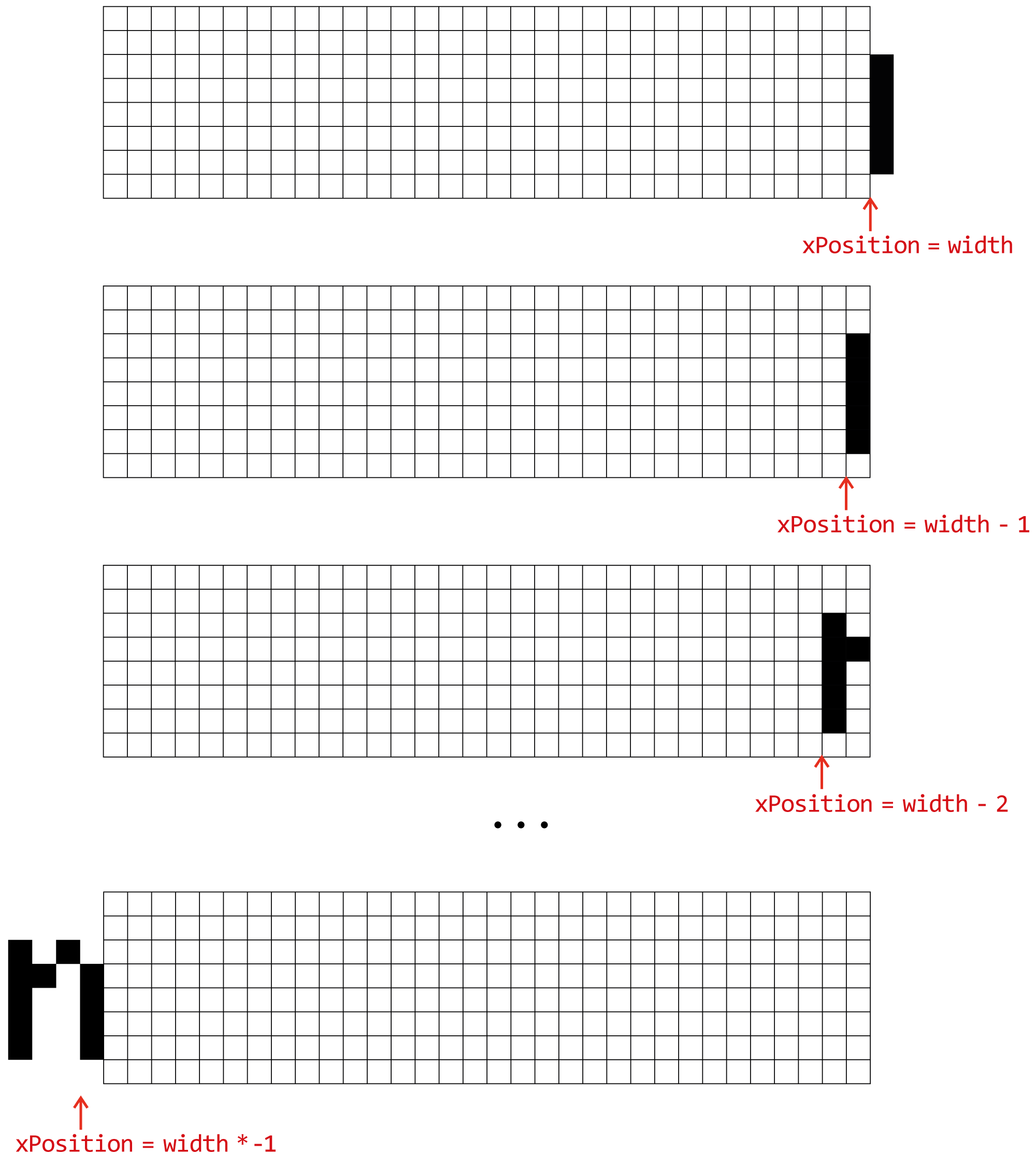
Because the font data includes the width, when the code iterates over subsequent characters, it can calculate the location it needs to start drawing at. This location is just called xPosition in the code, and each time a character is drawn on the display, its width and an additional space is added to the xPosition. As the code loops, all of the (x,y) coordinates returned from the font have this xPosition added to them making sure that the characters are drawn in sequence. This continues until the loop reaches the width of the display, where it stops drawing extra characters that would flow off the side.
Writing scrolling text is mostly the same, with one subtle change: the xPosition starts out at the right hand edge of the display. This means that when a message is first received, the xPosition — the initial offset, will equal the display width and no pixels will be drawn.
The scrolling text implementation is relatively simple — it is a loop that decrements that xPosition until it equals the total width of all the characters, as a negative number. So, if the text string has a total width of 100 pixels, it’ll keep on drawing, and decrementing the xPosition, until the xPosition equals -100. This scrolls the text across the screen.
The code on the hardware only ever draws pixels for the characters that will be visible on the display which means that memory is saved by not converting every character into pixels ahead of time.
There is another advantage to this approach — if you refer back to the data that is being sent as part of SetTextMessage, one of the values in the message header is a “scroll interval”. This scroll interval is the time delay between scrolling a single pixel to the left. This is what sets the speed of the scrolling. As the animation is played, the code pauses execution every time it scrolls. This loop prevents control being returned to the main Arduino loop, which would trigger receiving more MQTT messages.
This approach makes it possible to use MQTT as a buffer without using up any memory on the device. When it finishes scrolling, it receives any subsequent messages that have been sent, and starts scrolling the next piece of text.
Testing the hardware
Deploying code to the microcontroller not only requires the device to be plugged in but also takes time for the code to be verified, compiled and then pushed to the device. This can sometimes take quite a while. In order to make debugging both the code running on the board and its support of different sized displays, the web app comes with a simulated version of the hardware display.
This is a visual, virtual representation of the display which runs transliterated code (from C++ to typescript). It contains ported versions of the Arduino libraries that the microprocessor requires (like AdaFruit_NeoPixel), which made it possible to write code that appears as though it uses the NeoPixel SDK function, but it is targeting a div in the markup, instead of a pixel on the display. This means that code for the board can be written in Typescript (a language I personally much prefer!), tested on the simulated board and, once functional, can be transliterated into C++ to be written to the board.
To validate this approach, it was necessary to transliterate a few of the NeoPixel test programs into TypeScript to run in the simulator. This helped to build confidence that the code that was being written would work similarly on the hardware devices. The simulator was close enough to the real hardware to be a good test target. Fortunately this held true, and the TypeScript code that was written transliterated across to C++ with very few changes.
The Remote LED Matrix Driver
The same codebase that is used here to scroll text, can be used to send pixels for interactive painting, or even send images across to the device (as long as they are sufficiently tiny to fit on the display) using the TypeScript SDK that was built to communicate with the hardware.
The message protocol that was designed to send the data over the wire can transmit any pixel data, so long as the hardware at the other end can process the messages that it receives.
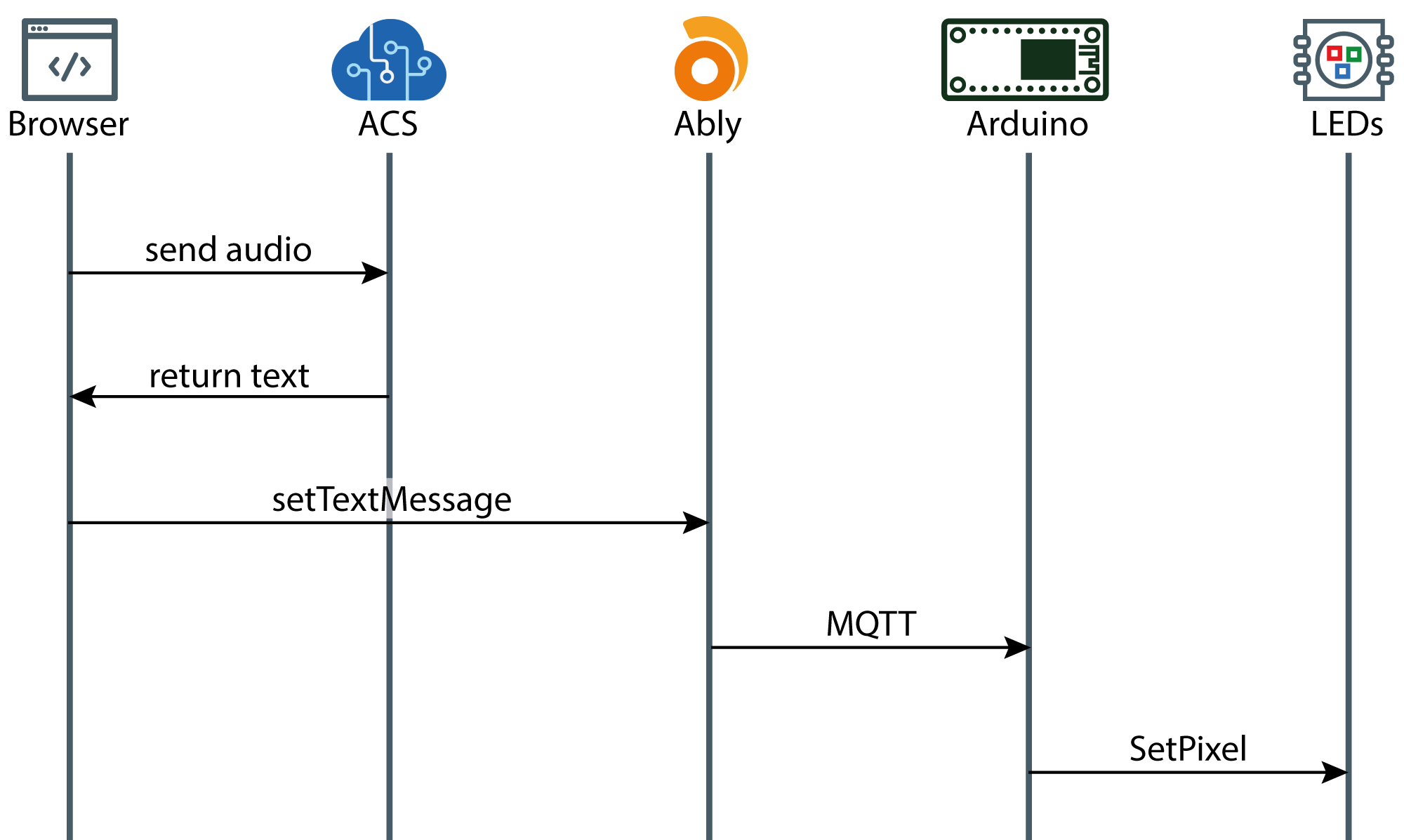
The final sequence diagram for the app, hardware and services in use looks like this:
What if I don’t want to wear a display?
Because there’s a message being sent via Ably every time a new transcription arrives, the web app also features a sharable “View” page that just displays the transcription text in real time on the screen. The user can share the URL of this to anyone that wants to open the page and read along.
The app contains a Share link that will trigger the operating system’s default sharing UI (at least on Windows and Android devices), using the Web Share API. This API is paint-dripping-wet new and not supported everywhere yet, so will be replaced with a “Copy Shareable Link” button on unsupported devices.
Show me the code
You can check out the code on GitHub: https://github.com/ably-labs/live-caption-demo
The live demo is up at: https://live-caption.ably.dev/
Where can we take this project next?
I started the project after seeing (and buying!) that LED mask in Cyberdog. I had hoped that I’d be able to hack, or reverse engineer that mask for use in this project, but its OEM hardware and software made that impossible for my skill level, so sadly it wasn’t really fit for this project. The displays that I ended up using don’t fit inside a mask comfortably, I bought these because they are what is currently readily available from hardware providers. The micropixel displays inside the mask don’t seem to be commercially available outside of those products just yet, but they probably will be soon, and this app will be ready when they are!
Azure Cognitive Services Speech service can do translation as well as transcription, it would be possible, with few changes to the code, and perhaps a few extra characters in the font, to make the mask display language translation, which could be very useful when travelling!
I, of course, showed the display and its accompanying app to my mother the last time I visited her and she was overwhelmed with what a difference it made to how well she could understand me in a mask. Yes sometimes the transcription is imperfect, but she was able to grasp the meaning of the words that she couldn’t hear and was able to look me in the face while speaking to me and that made all the difference. I hope that someone will take this idea and really run with it, because it could make a difference to so many people during this pandemic, and into the future.




