You can also read our recent post on SQS FIFO Queues, which looks at why converting a distributed system to FIFO and exactly-once message processing requires considerable user effort and what to bear in mind if planning to implement this.
In this article I explore the juxtaposition of a pub/sub fan-out messaging pattern and a queue based pattern, and why both are sometimes needed. Finally, I look at the solution to this problem.
A pub/sub pattern is designed so that each message published is received by any number of subscribers. This pattern is used by most realtime messaging providers, including Ably. Queue based patterns on the other hand typically require that each message is received only once by a single subscriber in a linear yet distributed fashion, often to be processed by workers.
A typical scenario where the pub/sub pattern works well
Take a company like Urbantz that rely on Ably to broadcast the position of vehicles as they traverse our roads. If you set out to build a similar GPS delivery tracking system, the flow of data between the vehicles and consumers wishing to track parcels may look something like this:
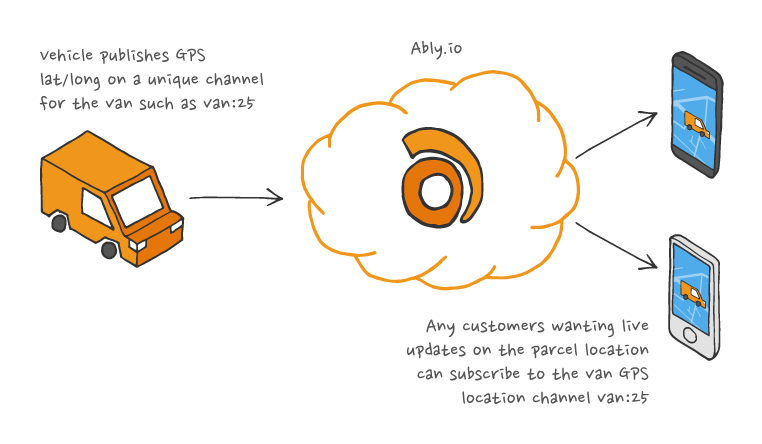
The pub/sub pattern and Ably's platform is a good fit because:
- The vehicle publishing its location is decoupled from anyone subscribing to messages. As the publishing client receives an acknowledgement (ACK), then it can trust that the data has been broadcasted successfully.
- Any number of devices can subscribe to updates on the channel dedicated to the vehicle, and those devices will see the position of the vehicle in real time.
When pub/sub feels like forcing a square peg into a round hole
Expanding on the example above, if you were to build a complete vehicle tracking system, you may have additional requirements to:
- Persist roll up data for the vehicle’s GPS locations into your backend database. For example, you may want to store the most recent lat/long every 15 seconds.
- Trigger actions as part of your workflow when a vehicle reaches its destination or when it’s delayed.
I’ve seen other realtime platforms mostly recommend approaching this problem in one of three ways:
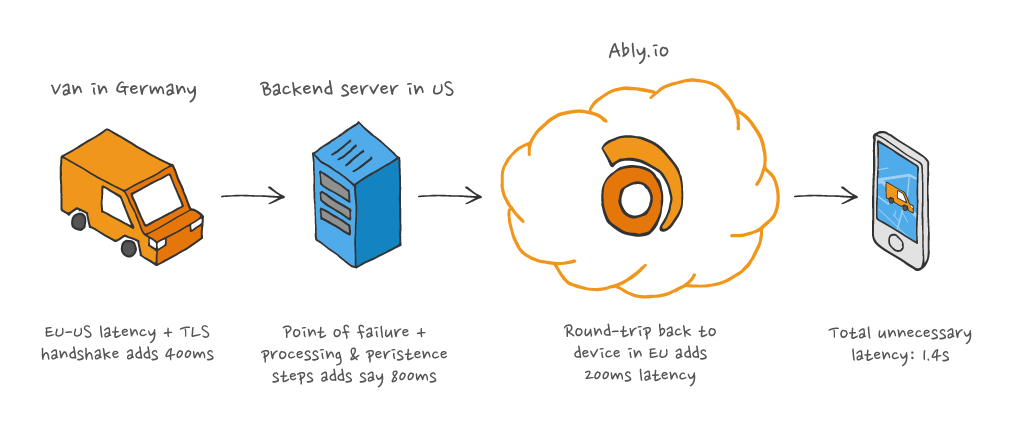
All data that would have been broadcast in real time is instead sent as an HTTP request to your own servers. This isn't ideal because:
- Any latency in your own servers will affect your clients
- If your servers are unable to cope with a sudden burst of realtime data then the lat/long data is lost
- You lose the benefits of a global resilient realtime platform that routes data efficiently i.e. data in EU is never unnecessarily routed through the US
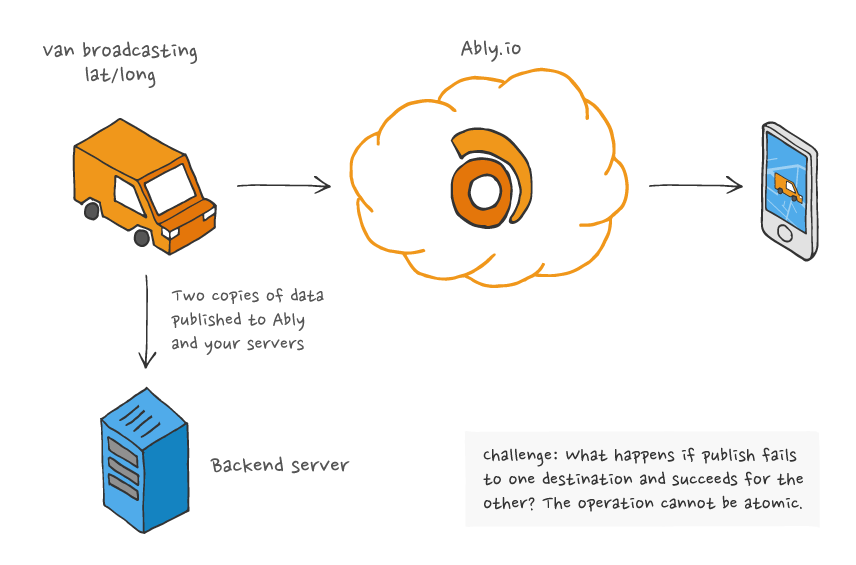
This solves the problem of latency and resilience by using Ably directly from the publishing client, but it does introduce a new problem:
- Operations can no longer be atomic. What does the client do if the publish to the backend server fails, yet the broadcast to Ably succeeds? A single failure can result in your client devices and servers having different representations of the state with no straightforward way to rectify the problem.
- Each publishing client has to do double the work and consume at least twice the bandwidth for each broadcast. On mobile devices, this matters.
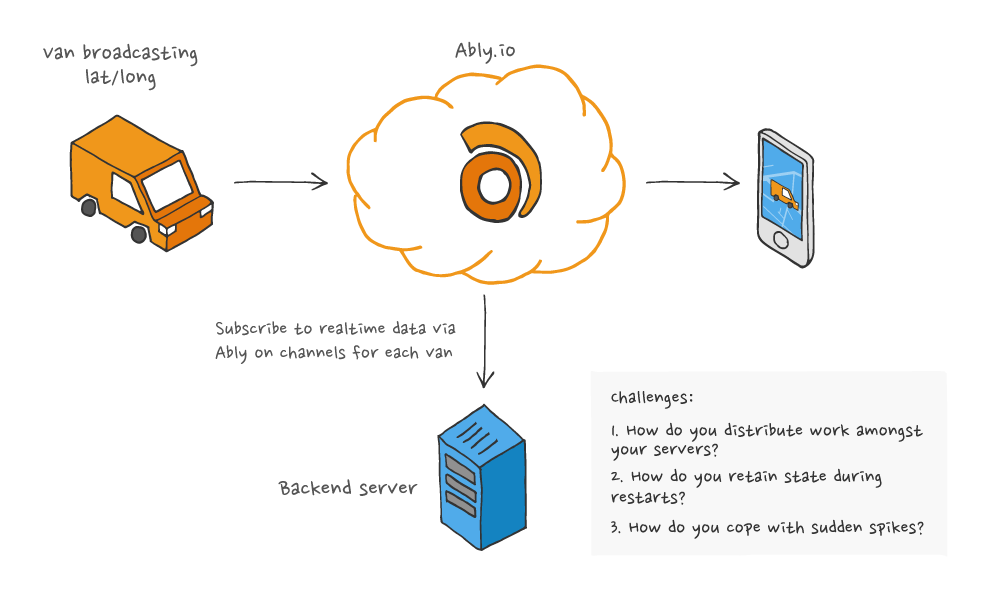
Our customers often find this approach seems like the most obvious answer to the problem, but it has many flaws and technical challenges:
- If you have a sudden sustained burst of realtime messages published across all your channels, your servers could easily fall behind. We typically retain connection state for two minutes, so if you fall behind by more than two minutes you’ve got problems and can expect data loss.
- How do you distribute the work amongst your workers? Assuming you had 5,000 channels with one message per second each, and based on your testing you know you can process 500 messages per second per server, then you will need to work out how you share the work out amongst your workers. The pub/sub pattern is a bad fit here as if you had 10 workers subscribed to all 5,000 channels each, they would all be processing all messages on all channels i.e. 5k messages per second each. The solution to this we most often see is to use a hashing algorithm to work out which workers subscribe to which channels. But this approach adds a lot of complexity especially when channels are dynamic and are added and removed on-demand.
- Your workers now need to maintain state. They need to know which channels are active at any point and need to ensure they can retain this state through redeploys and crashes. This is hard, especially when you have channels frequently opening and closing. WebHooks can alert you to channels opening and closing, but what happens if your system fails to process one of these requests correctly? The answer may be a periodic re-sync step, but therein lies yet more complexity.
- If one of your workers is offline for more than two minutes then you will likely lose data. You can use our history feature (aka persistence) to retrieve missed messages. But that again adds complexity, unnecessary storage of data for these edge cases, and bottlenecks in how quickly you can catch up given history requires a REST request per channel per batch.
- You now need stateful servers instead of stateless servers. I'm personally an advocate of stateless servers where possible as unnecessary complexity can often be avoided.
What's the soltuion to all this?
Message queues: the right way to process realtime data on your servers
Before we dive into why message queues are the answer to this common problem, I want to quickly explain what queues are and how they differ significantly from Ably's pub/sub channels.
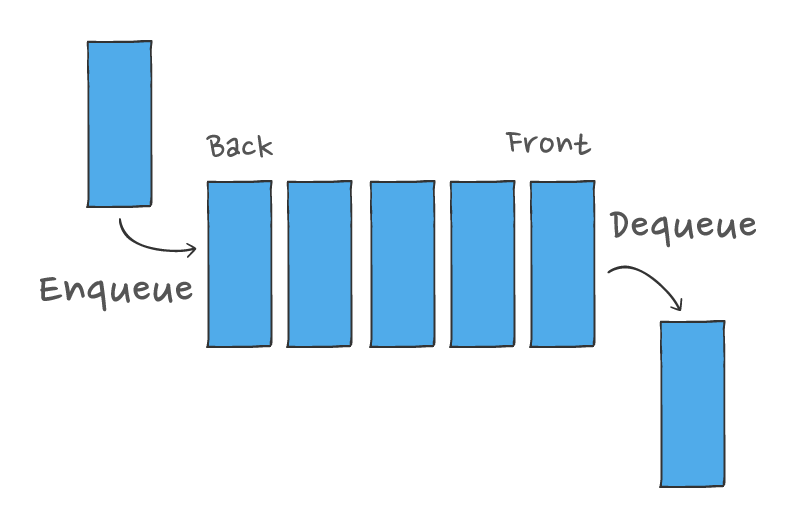
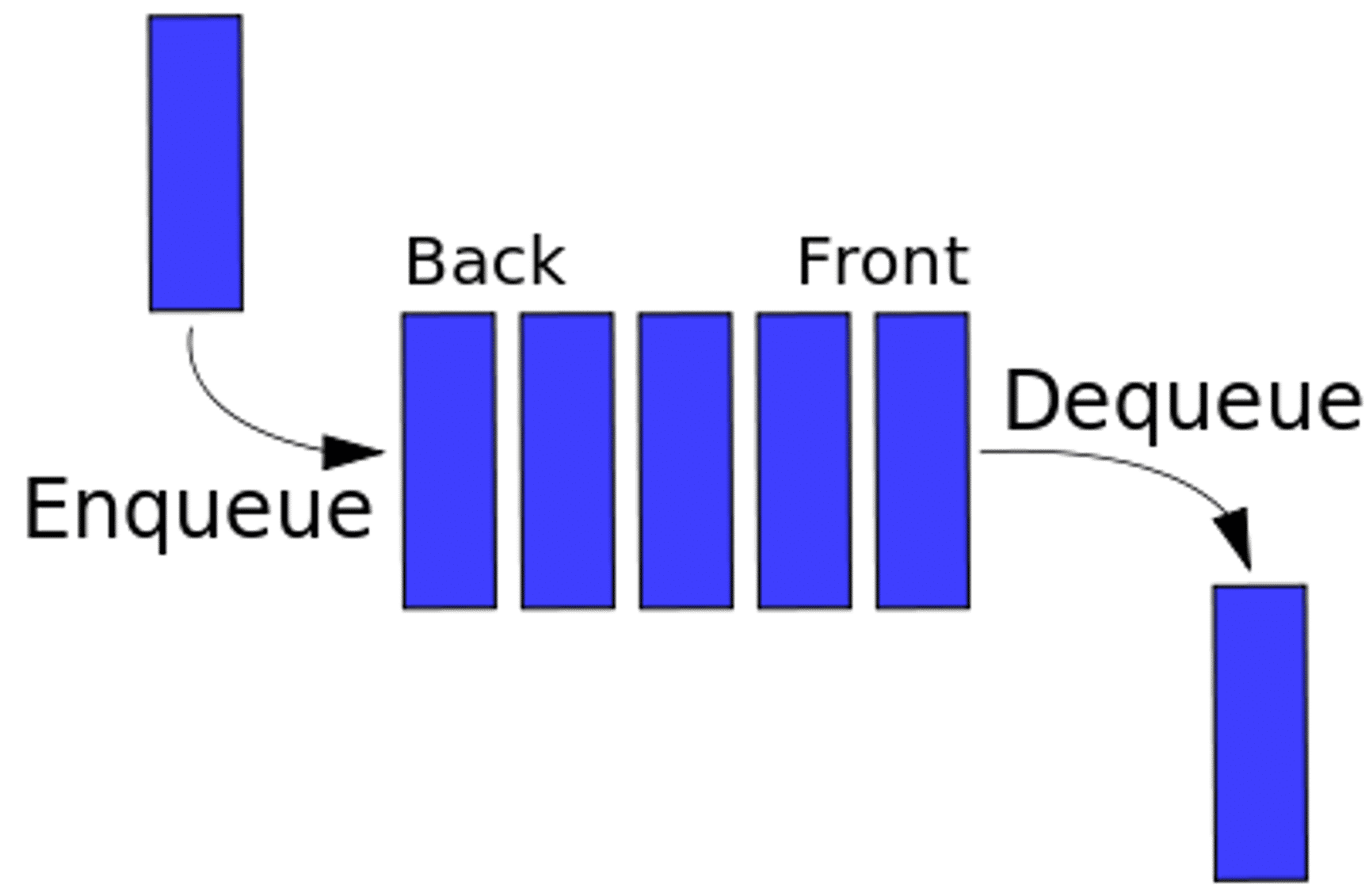
- Queues provide a buffer to cope with sudden spikes
Data messages added to a queue are stored and held to be processed later. As a result, adding messages to the queue is completely decoupled from subscribers wishing to take messages off the queue. If subscribers cannot keep up, the queue simply grows and the workers are given some breathing room and as much time as they need to catch up. - Queues fan out work by releasing each message only once
Unlike Ably’s channels which deliver messages to any number of subscribers, queues will only deliver messages in the queue to one subscriber. As such, if you have 10 workers processing 5k messages per second, each will receive 500 of those messages per second. Therefore, each worker can process the data it receives without having to worry about whether other workers have received and processed the same data. This allows the workers to be designed in a more straightforward, stateless way. - First in first out
Queues by default operate using FIFO which means first in, first out. This approach ensures that if a backlog of messages build up, the oldest messages are processed first. Our engineering team recently wrote about some considerations when implementing Amazon SNS FIFO Queues into a distributed system. - Queues are real time in nature
If your subscribers pick messages off the queue at the rate they are added, then the additional latency added should be in the low milliseconds. In practical terms, a queue does not add latency. - Data integrity
If a worker picks a message off the queue, but does not send an acknowledgement of the message being successfully processed, then after a short period the message will become available on the queue again to be processed by the next available worker. This feature ensures that messages are never lost.
How Ably provides queueing for our customers
If we now reconsider the problem of how to build a vehicle tracking service and process the data using your own servers, we can recommend a the following approach using an Ably message queue:
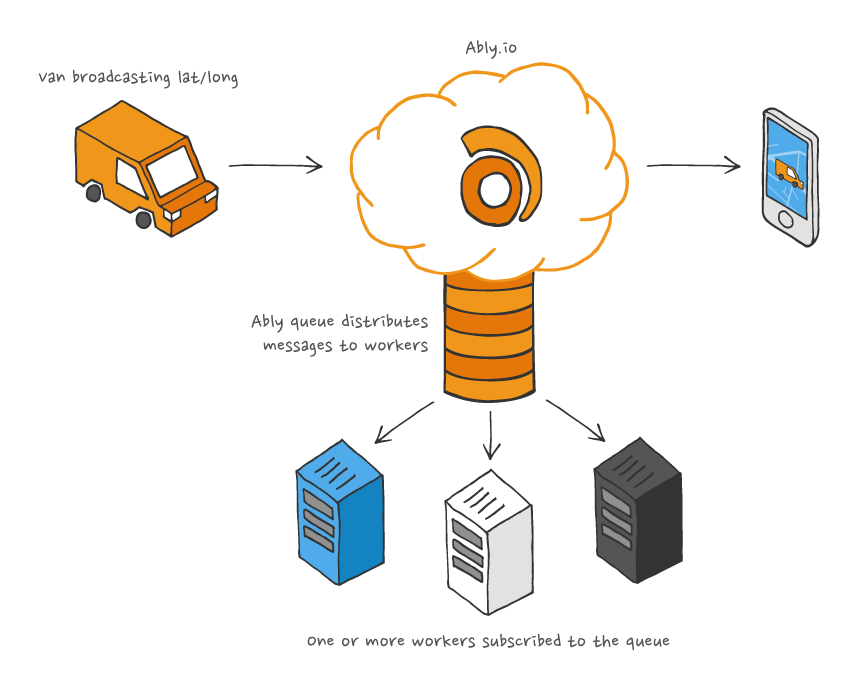
The benefits of this approach are:
- Rules are applied to messages published on channels that copy messages from the realtime channel to a queue asynchronously. This ensures that messages are published with low latency to subscribed realtime clients on the channel, yet also added onto a queue immediately.
- If you are unable to process the queue quickly enough, we provide a reliable buffer ensuring we hold onto messages until you are ready to process them.
- Any failure to publish a message on a channel will not result in the message being added to the queue. The operation is atomic.
- Your workers can be scaled up and down as you require without having to worry about sharding the work between them. Our queue service automatically ensures that each message is delivered to only one worker.
- This encourages our customers to have a more stateless design in their systems and thus significantly reduce the complexity.
Some queue specifics
The following data types are supported by message queues:
- Messages — get notified when messages are published on a channel
- Channel lifecycle events — get notified when a channel is created (following the first client attaching to this channel) or discarded (when there are no more clients attached to the channel)
- Presence events — get notified when clients enter, update their data, or leave channels
If your expected volumes are low, we support WebHooks. WebHooks provide a means to push messages, lifecycle events and presence events to your servers over HTTP reliably.
If you are interested in using message queues, or have any questions, check out the docs or get in touch with us.