We’ve bet on well supported open source projects like Google’s V8. Following an upgrade from Node.js v6 to v8, this bet has paid off. Our latencies are more consistent and our global infrastructure server costs have gone down by almost 40%.
At Ably Realtime, a distributed pub/sub messaging platform, we use a wide array of technologies in our realtime stack including Elixir, Go and Node.js. Whilst Node.js is not often our first choice for new services, our core routing and front-end layers are built with Node.js, which, in spite of some well known shortcomings, continues to serve us very well.
Whilst we are continuously optimizing our infrastructure running costs, there is always a trade-off between allocating engineering resource to focus on new revenue (features) vs reducing costs (optimizing performance).
In the majority of cases, for our high growth tech business, revenue growth is where our focus lies. Fortunately though, as we have bet on a number of underlying technologies that are incredibly well supported by the community, we continue to get material cost reductions without much engineering effort.
Case in point is a recent Node.js upgrade from v6 to v8. As an effect of that, we have seen two significant improvements:
Under load, performance is less spikey and more predictable
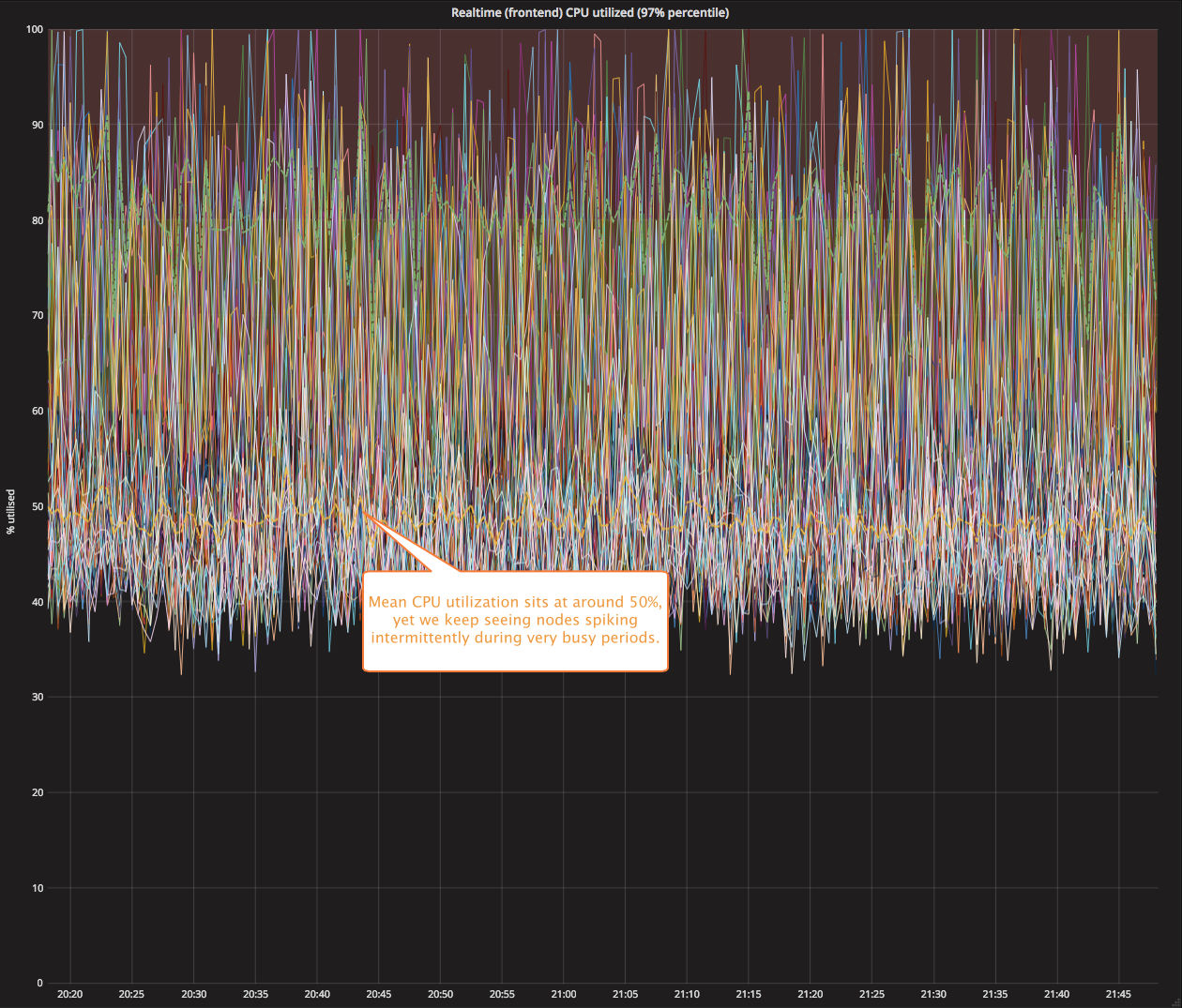
In the graph below, you’ll see that in our clusters containing 100s of nodes, during the busiest times we saw nodes spiking to nearly 100% for brief periods in spite of the mean CPU utilization sitting at around the 50% mark.
Yet once we completed the upgrade to Node.js v8, with comparable load on the cluster, we see far more predictable performance without the spikes:
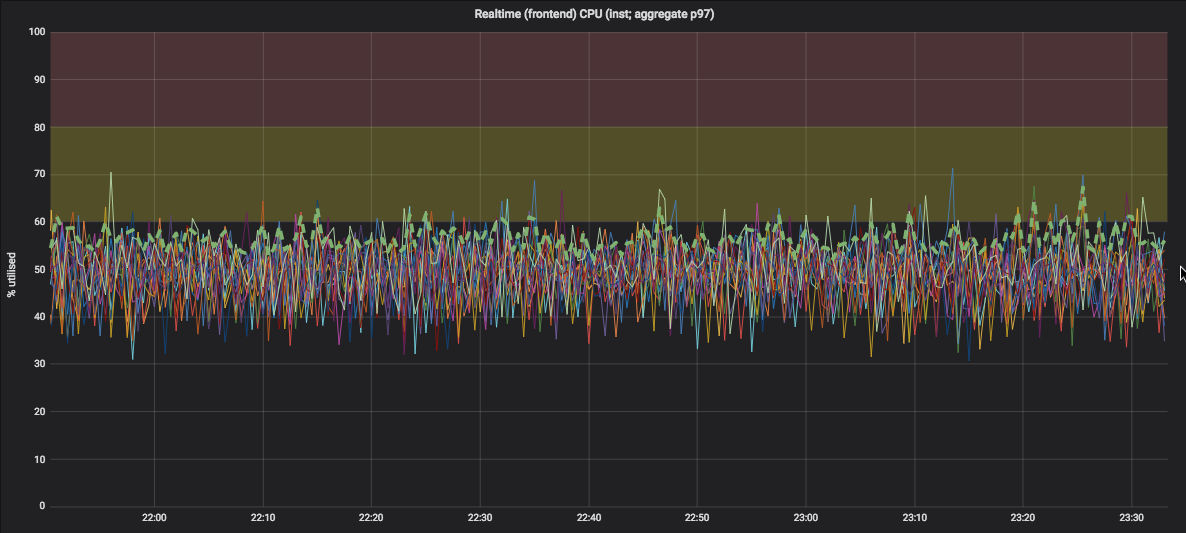
We can speculate what changes in the underlying V8 are responsible for this, but in reality the V8 JavaScript engine is improving on many fronts (specifically the compiler, runtime and garbage collector) which all collectively play a part.
Bang for our buck has vastly improved: circa 40% real world saving
When we performed load testing in our lab on Node.js v6 vs Node.js v8, we saw that in the said region, there was a 10% increase in performance. This is not all that surprising as the v8 performance improvements are well known. However, once we tested v8 in one of our isolated clusters servicing real world production traffic, the benefits were far more significant. Whilst Google V8’s TurboFan and Ignition gave us the ability to increase the rate of operations on the same underlying hardware, the improvements mentioned above (that made the performance more predictably smooth on each node) gave us more confidence in regards to the true spare capacity we had in each cluster. As such, we were able to run with less nodes under most conditions.
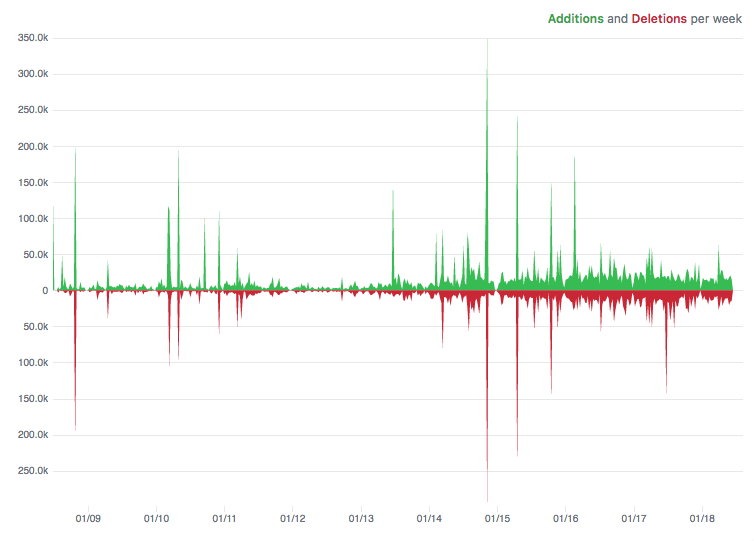
As you can see below, in one of our busier clusters running Node.js v8, we were able to reduce our raw server costs by circa 40–50%:

If performance matters, then bet on technology that has the engineering muscle and drive to continuously optimize, so you don’t have to.
Whilst the benefits we experienced from this upgrade could be considered to be a lucky win for us, we don’t see it that way. Building an Internet-scale system without Google-scale resources, requires a strategic approach to your technology choices. If you focus on projects that have a community of engineers focused on improving performance, then you’re bound to have some luck along the way.
If we started again from scratch today, we’d probably not be using Node.js as extensively as we use it now. However, in 2013 when we started Ably Realtime, we chose Node.js for our core routing layer as it provided us with technology well suited to the high I/O workloads. It also encouraged rapid development cycles, and at the time the technology performed well versus other similar technologies.

One bet we took when choosing Node.js, was that over time, it would continue to get faster, and it has, significantly so. That’s no surprise, of course, given the Google V8 engine is used in their Chrome browser. Since 2015, there’s been an average of around 20,000 lines of code changing each week in the V8 engine. That’s a mammoth amount of effort from a highly skilled engineering team.
We’ve made similar bets with other technologies we’ve chosen, which also have a large group of contributors focused not just on features, but also on continuous performance optimizations such as:
- gRPC for our RPC layer (again sponsored by Google)
- Cassandra for our persistence layer
- Golang for our network services and workers
Some additional notes:
- For those astute readers, you may be wondering why we took so long to upgrade to Node v8 when it’s been out for over a year. The underlying reason is that we provide a service where our customers expect us to be up 100% of the time, so our approach to third party dependencies is, where possible, to use very stable and well supported versions. In the case of Node v8, the LTS version was only officially released at the end of 2017.
- We realized some time back that the most likely reason we would not be able to honor 100% uptime aims, would be due to a software fault, not a hardware, infrastructure, or a network fault. Our infrastructure has redundancy in every layer of the service, which is how we are able to ensure continuity in spite of hardware and network failures. However, that infrastructure offers no protection from a software fault that is deployed globally. As such, we localize changes to infrastructure on a per region basis to minimize the impact of changes, and do the same for our software changes. However, when it comes to dependencies we upgrade, we always tread very carefully as it’s not practical to understand, in depth, the changes that have been made upstream. As a result, our approach to dependency updates is slower, requires more testing, and is deployed in stages from one instance, to one cluster, and then onto the global service. This allows us to measure the impact of a change of a dependency in terms of latency, errors, resource utilization before we decide to roll it out more widely.
- Rising Stack have kindly summarized the most significant changes in Node v8.
- Node v10.4 and V8 6.7 is looking like it’s going to significantly improve GC performance as a result of concurrent marking. We’ll post an update once the changes land in an LTS version of Node.