Here at Ably we are have been working on our distributed realtime messaging platform, global cloud network, and realtime APIs for over six years, so we think we're qualified enough to take a stab at defining the skills and knowledge that a distributed systems engineer needs.
The concepts a distributed systems engineer needs to know
- Microservices or SoA is not a distributed system
- Understanding hash rings is a pre-requisite
- Gossip protocols and consensus algorithms underpin everything
- Eventually consistent data types and read/write consistencies
- Deep understanding of network protocols
Microservices or SoA is not a distributed system
Here's an example of a simplistic design of a service based architecture with horizontal scalability:
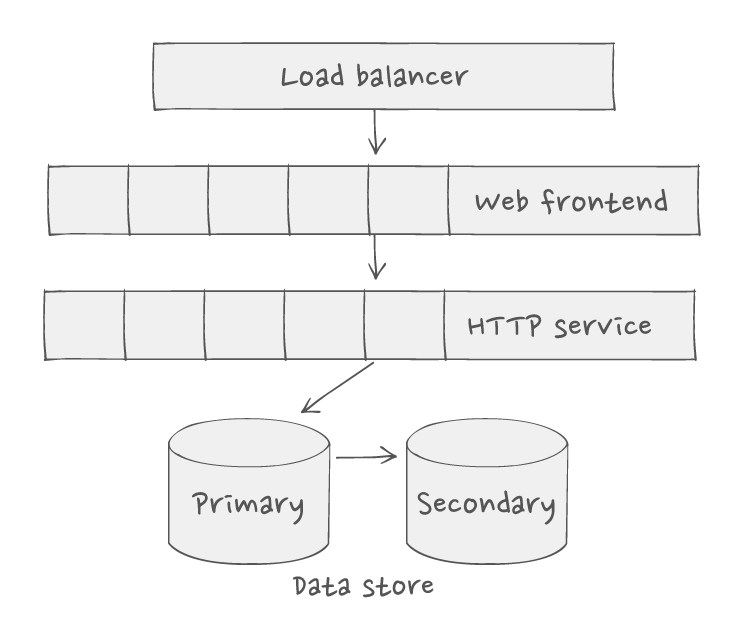
There’s not much “distributed” about this system. There are multiple hosts and network interconnections but they are tightly coupled. And their network interactions are reliable, have low-latency, and are predictable. Genuinely distributed, in our view, means:
- Systems where nodes are distributed globally
- Network interactions are unpredictable and can create partitions
- Nonetheless those nodes work together to create a predictable outcome
Distributed systems, at scale, involve state being distributed and re-balanced across the system, reacting as nodes are added and removed, and they do this in spite of the unpredictability that is inherent in a global system.
Understanding hash rings is a pre-requisite
If you think a hash ring has something to do with a criminal cannabis organization, then that’s certainly amusing, but unfortunately means you’re missing knowledge of a common pattern used for distributed systems.
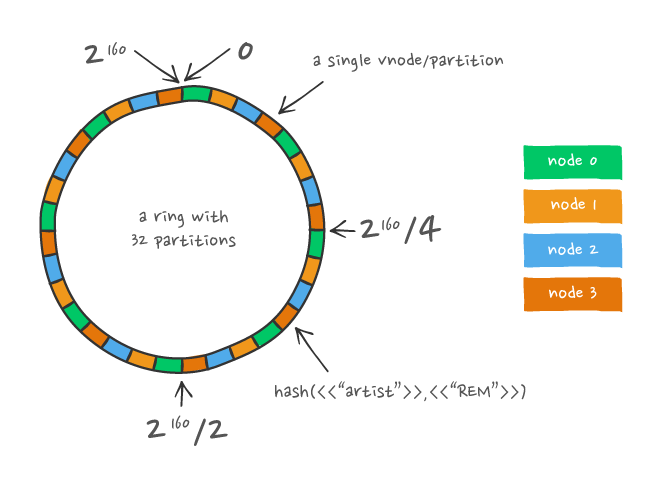
If the above doesn’t look familiar, then we recommend you start by diving into how popular distributed systems work, all of which rely on the ideas behind a consistent hash ring. See:
Gossip protocols and consensus algorithms underpin everything
Large distributed systems usually have to track changes in cluster topology in response to network partitions, failures, and scaling events. Various protocols exist to ensure that this can happen, with varying levels of consistency and complexity. This needs to be dynamic and real time because:
- Nodes come and go in elastic systems
- Failures need to be detected quickly
- Load and state need to be rebalanced in real time
With a stateful system like Ably, state also needs to be moved in real time between new and old nodes whilst providing continuity throughout.
If you have never worked with Gossip or consensus algorithms, then I recommend you read up on:
- Gossip protocol
- Paxos protocol
- Raft consensus algorithm
- Popular consensus backed systems like etcd and Zookeeper, and gossip backed systems like Serf
Eventually consistent data types and read and write consistencies
Generally in a distributed system, locks are impractical to implement and impossible to scale. As a result, trade-offs need to be made between the consistency and availability of data. In many cases, availability can be prioritized and consistency guarantees weakened to eventual consistency, with data structures such as CRDTs.
If you’re not familiar with CRDT or Operational Transform, the concepts of variable consistencies for queries or writes to data in a distributed data store, then you’ve got some reading to do:
- Operational Transform — originally implemented by Google in their Wave product and now in Google Docs. It has uses in collaboration apps, but OTs are complex and not widely implemented.
- Conflict-free Replicated Data Types or CRDT provides an eventually consistent result so long as the data types available are used. Used by Riak distributed database and presence in Phoenix.
- Consistency levels for both read and writes in distributed databases like Cassandra.
Deep understanding of network protocols
In a distributed system, you’ll almost certainly be working within all layers of the networking stack. Ably relies extensively on various higher level protocols such as HTTP, WebSockets, gRPC, and TCP sockets. But without a deep understanding of those protocols and the full stack of protocols they rely on all the way down to the OS itself, you’ll likely struggle to solve problems in a distributed system when things go wrong.
Take for example the following request or WebSocket connection which involves all of the following. At each layer you should be confident in your understanding and ability to debug problems at a packet or frame level:
- DNS protocol and UDP for address lookup
- File descriptors (on *nix) and buffers used for connections, NAT tables, conntrack tables etc.
- IP to route packets between hosts
- TCP to establish a connection
- TLS handshakes, termination and certificate authentication
- HTTP/1.1 or more recently 2.0 used extensively by gRPC
- WebSocket upgrades over HTTP
And that’s not all…
From our perspective of operating a truly global and distributed system, a working understanding of the specific concepts described above is what we expect from a distributed systems engineer. Before that you need to also be a solid systems engineer. This requires you to have fundamentals in place such as programming languages, general design patterns, version control, infrastructure management, and continuous integration and deployment systems.

About Ably
Ably provides cloud infrastructure and APIs to help developers simplify complex realtime engineering. Organizations build with us because we make it easy to power and scale realtime features in apps, or distribute data streams to third-party developers as realtime APIs.
We're growing like crazy and hiring across our engineering and commercial teams. We have more than 10 open jobs, including Distributed Systems Engineering, so check out our job board ?.
And if you’re interested in finding out more, please do reach out to Ably on Twitter or contact us!