Exactly-once is a desirable (if not critical) message delivery guarantee and a remarkably complex engineering challenge to solve. In this blog post, we will look at what exactly-once means in the context of distributed pub/sub systems, and the exactly-once guarantees that the Ably realtime pub/sub messaging platform provides. Ably often acts as the broker in data streaming pipelines: publishers send messages to our platform, and we deliver these messages to subscribers. As a broker, Ably provides regional & global fault tolerance, which ensures message availability and survivability. We also offer a set of capabilities via SDKs that enable clients to use idempotent publishing, and recover in the event of a failure while resuming precisely where they left off, with no lost or duplicate messages.
Exactly-once delivery is one of the hardest engineering challenges
In the context of distributed pub/sub systems, exactly-once is a popular concept and a desirable, if not critical, system property. It also leads to confusion and diverging opinions within the development community. On the one hand, some argue that exactly-once is simply unachievable. On the other hand, there are systems such as Kafka that claim to support exactly-once semantics.
We believe that a lot of the confusion around the concept has to do with the fact that there's no clear definition of what exactly-once actually means. It's arguably impossible to come up with a definition to satisfy everyone and every use case. That's because exactly-once can mean different things for different systems and different use cases. Regardless of how you look at it, though, exactly-once is, without a doubt, a distinctively complex engineering challenge.
Let’s now define what exactly-once means for Ably in particular. In our case, exactly-once is a guarantee that once acknowledged, a message published to Ably is delivered to a consumer precisely once, even in the context of individual system components failing. Note that most often, Ably is used to deliver messages in real time directly to end-user devices.
It’s crucial to mention that exactly-once is a system-wide property, and you only achieve it if all the constituent components play their part. This doesn’t mean that all the components must display exactly-once characteristics. For example, in our case, you can have a publisher that displays at-least-once behaviour. However, Ably provides an idempotent interface, which cancels out the fact that the producer may occasionally publish messages more than once. As long as at the other end of the pub/sub pipeline each message is delivered to subscribers precisely once, exactly-once behaviour is achieved as a whole.

Types of messaging semantics
Before we dive deeper into exactly-once delivery, let’s review the main types of messaging semantics. When a system is fully operational and working as intended, exactly-once delivery is the behaviour you generally expect. However, we must also consider how faults in the pub/sub system or, indeed, clients affect this behaviour. While most components fail independently in a distributed pub/sub system, without directly impacting other components, the overall quality of service can be affected. Depending on how the system behaves when failures do occur, you get several different types of messaging semantics:
- At-most-once semantics. The easiest type of semantics to achieve, from an engineering complexity perspective, since it can be done in a fire-and-forget way. There's rarely any need for the components of the system to be stateful. While it's the easiest to achieve, at-most-once is also the least desirable type of messaging semantics. It provides no absolute message delivery guarantees since each message is delivered once (best case scenario) or not at all.
- At-least-once semantics. This is an improvement on at-most-once semantics. There might be multiple attempts at delivering a message, so at least one attempt is successful. In other words, there's a chance messages may be duplicated, but they can't be lost. While not ideal as a system-wide characteristic, at-least-once semantics are good enough for use cases where duplication of data is of little concern, or scenarios where deduplication is possible on the consumer side.
- Exactly-once semantics. The ultimate message delivery guarantee and the optimal choice in terms of data integrity. As its name suggests, exactly-once semantics means that each message is delivered precisely once. The message can neither be lost nor delivered twice (or more times). Exactly-once is by far the most dependable message delivery guarantee. It’s also the hardest to achieve.
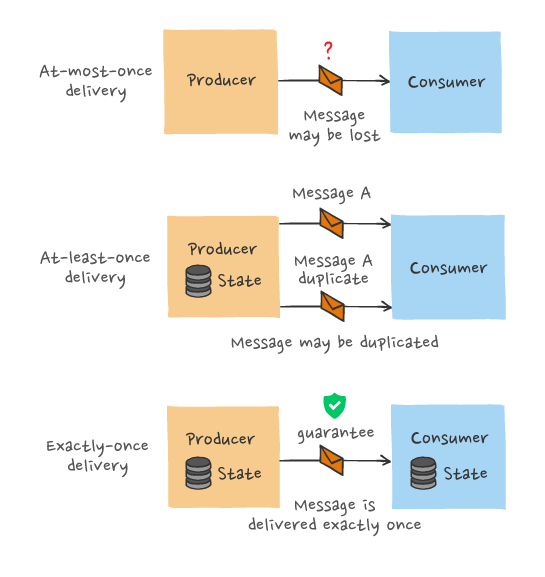
What most distributed pub/sub systems can genuinely guarantee is mostly-once delivery. This means that when the system is functioning as intended, messages are delivered exactly once. However, when failures are involved, there’s always a chance some messages will be delivered either at-most-once or at-least-once.
Failures that prevent exactly-once delivery
To demonstrate just how hard it is for distributed pub/sub systems to achieve exactly-once semantics, we must talk about failures—specifically, components that can fail and how these failures can be mitigated.
Publisher failure
When a publisher fails, some sort of recovery process takes place. Depending on its design, after recovery, the publisher may reattempt to publish a message that has already been sent to and acknowledged by the broker. In such an event, the publisher failure causes at-least-once behaviour. Another scenario is that the publisher’s recovery procedure fails to realise that the publish attempt failed, which leads to at-most-once behaviour.
A strategy often used after a publish failure is to retry publishing the same message a fixed number of times. This is a pragmatic approach, but unsatisfactory in the context of exactly-once. Imagine that the publisher recovers and unsuccessfully tries to republish the same message five times, and then gives up. Practically none of the three semantics is achieved. To mitigate publisher failures Ably supports idempotent publishing, which ensures that regardless of how many times the same message is published to Ably, it will be delivered to subscribers exactly-once.
Broker failure
A broker failure has the potential to lead to all sorts of issues, including data loss. That’s why it’s recommended to design your system around the idea of mitigating or preventing loss of data. From a producer perspective, this could mean having the ability to publish messages at-least-once, so they can be resent to the broker if needed.
From a broker perspective (Ably included), let’s start by reviewing what a message ACK means. Obviously, it’s an acknowledgment that a published message has been received. Additionally, it should also imply that no subsequent failure will result in that message not being delivered to subscribers. In other words, it should be an acknowledgment that the broker provides sufficient redundancy to ensure continuity of service and onwards processing, even in the context of multiple infrastructure failures. Of course, nothing can be done to prevent or mitigate certain types of critical failures. When that happens, the sensible thing for the broker to do is to respond with a failure response (with HTTP, this is typically a 5xx status code), indicating clearly to the producer that the publish attempt was unsuccessful.
Subscriber failure
The most common subscriber failure that prevents exactly-once delivery involves short disconnections. For example, a client app on a mobile device will disconnect and quickly reconnect when the user switches from a mobile data network to a Wi-Fi network or goes through a tunnel. To counter this scenario and ensure exactly-once behaviour, the stream of messages must resume precisely where it left off when the subscriber recovers. For this to be possible, the connection state must be persisted and resynced when the subscriber reconnects.
If the broker is the one keeping track of the last message sent, you are unlikely to provide exactly-once semantics. That’s because a broker might send a message, and the subscriber might successfully receive it and then disconnect before sending an ACK to the broker. In such a case, once the subscriber reconnects, the broker will resend the respective message (at-least-once semantics) since it has no way of knowing that the subscriber had received it before disconnecting.
To ensure exactly-once behaviour, the responsibility of keeping track of the last message received should sit with the subscriber - something we also do at Ably, via serial numbers. This way, when the subscriber reconnects, it notifies the broker of the last message it has received so that the stream can be accurately resumed from a point in time.
Exactly-once semantics use cases
In the world of distributed pub/sub systems, exactly-once semantics has been and continues to be extremely hard to achieve. Equally, almost everywhere you look in software development, exactly-once is a highly desirable system-wide property, if not an essential one. For example, exactly-once is crucial for most transactional messaging use cases. At its core, a transactional message is triggered by a consumer action, and it usually includes necessary or high-priority info, e.g., a bank balance inquiry or an order confirmation.
Ordered operations represent another use case where exactly-once is fundamental. Let’s say you want to use delta compression to only stream changes from the previous message to subscribers each time there’s an update. To achieve this, you need to use a transport that ensures data integrity through guaranteed message ordering and exactly-once semantics.
If not crucial, exactly-once is at least highly desirable, because it improves overall system predictability and provides better experiences to users in general. For example, think of push notifications being delivered twice because your system supports at-least-once delivery rather than exactly-once. A duplicated push notification is not the end of the world, but it can become frustrating for the end-user if it happens frequently.
Even if your current use case doesn’t explicitly require exactly-once behaviour, it’s better for your system to exhibit this property. That’s because it’s a solid guarantee, making your solution more dependable and simplifying future engineering efforts to support use cases that may require exactly-once semantics.
When we talk about exactly-once, we must not forget that it’s a system-wide capability, where multiple components play a role. The hard engineering challenge is to get these components to work together to ensure that messages are delivered exactly once. For example, suppose your message transport layer only exhibits at-least-once characteristics. In that case, you have to build your own capability on the publisher and subscriber end to handle deduplication and idempotency in order to achieve exactly-once delivery.
What exactly-once guarantees does Ably provide?
Ably is a globally-distributed realtime pub/sub messaging platform. We often act as the broker in data streaming pipelines: producers publish messages to Ably, and we deliver these messages to subscribers. Ably is engineered to provide superior quality of service and data integrity guarantees, including exactly-once semantics.

Before we go into more detail about the exactly-once capabilities Ably provides, it’s worth reiterating that exactly-once is a system-wide behaviour that is achieved only if all the constituent components play their role and work together towards achieving it. We guarantee all Ably components are designed to play their part in delivering exactly-once semantics. However, we cannot guarantee that your end-to-end pipeline, which may involve multiple services and components aside from Ably, also achieves an exactly-once behaviour.
Idempotent publishing and Ably
In general, when a publisher submits a message to the Ably platform, they will either get a success response (ACK), signifying that the message is accepted for onward processing, or an error response, which is a complete rejection – no onward processing will take place for rejected messages. On rare occasions, the publisher might not receive the ACK due to reasons not in our control, such as network failures. If this happens, the client has no way of knowing if Ably has received the message, so they have to resend it.
However, that’s not an issue, because Ably can identify incorrectly resent messages through idempotent publishing. This can be achieved by enabling idempotentRestPublishing in the ClientOptions object. When idempotent publishing is on, our SDKs automatically assign a unique id to each message, ensuring that subsequent retries will not result in duplicate messages. Here’s how publishing a message with a unique id looks like:
var rest = new Ably.Rest('ABLY_API_KEY');
var channel = rest.channels.get('test-channel');
channel.publish([{data: 'payload', id: 'unique123'}])
Additionally, messages IDs can also be supplied directly by clients. For context, Ably uses a globally-distributed edge network to provide system performance, availability, and reliability guarantees. With this in mind, client-supplied IDs enable producers to freely publish the same message from one or more workers in their system, without fear of duplication at the consumer end.
All messages on a given channel, in a given region, are indexed based on these unique IDs. When a message is published to Ably, we perform an existence check for already-accepted messages with the same identifier and discard any duplicates.
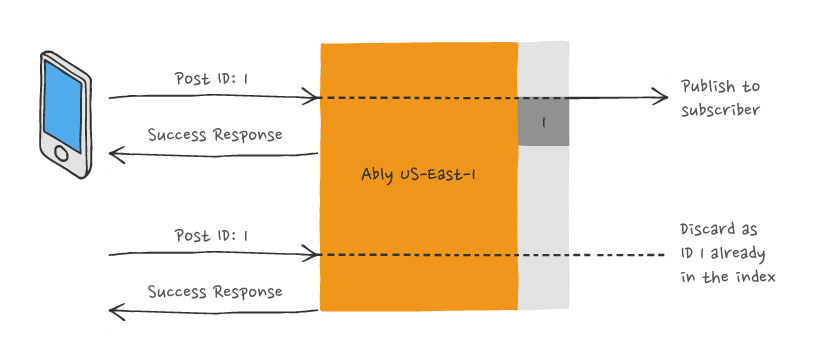
Of course, there's also the possibility that a second attempt to publish a message is made in a different region than the first one. For example, let's assume the first attempt, which is successful, occurs in region A. There's a second attempt to publish the same message, in region B. Based on this, there are two scenarios worth covering:
- The successful publish in region A results in the message being propagated to region B. Therefore, the message is also included in region B's index. With that in mind, when a publish reattempt takes place in region B, the resulting message is discarded since it's already present in region B's index.
- The republish in region B happens so fast that it reaches region B's index before the message from region A is propagated. When the region A message finally reaches region B, it's discarded as a duplicate. Equally, when the successful publish attempt in region B propagates to region A, it's also discarded.
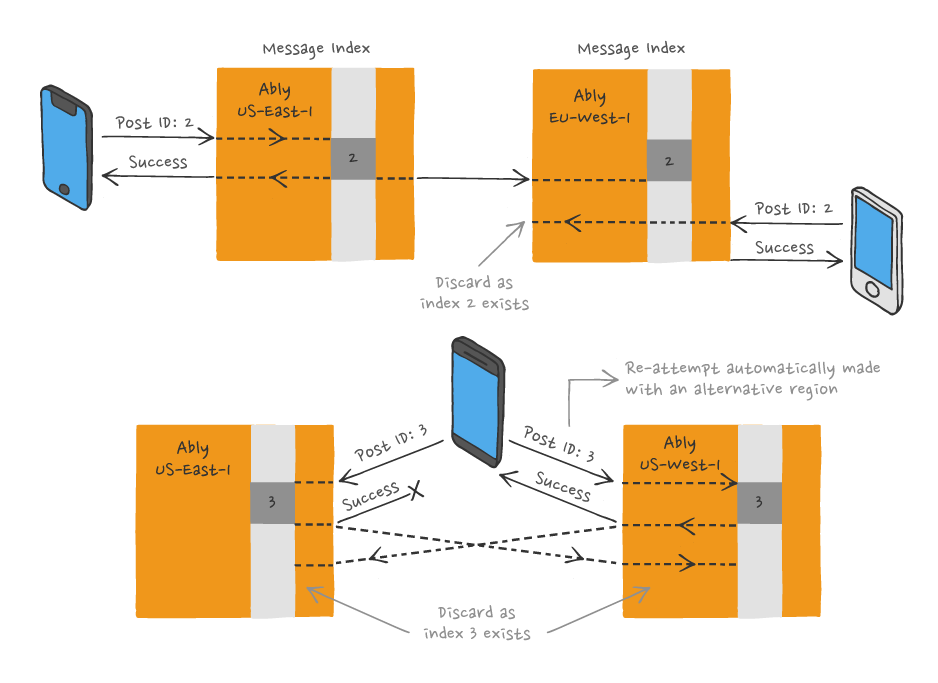
As a summary, if a message is published to Ably at-least-once, from a consumer perspective, the effect is still as if it was only published once. We guarantee that when we deliver the respective message to subscribers, it’s delivered exactly-once. To find out more about idempotence in general and dive deeper into Ably’s idempotent publishing, have a read of Idempotency - Challenges and Solutions Over HTTP.
Ably as the broker
The broker, much like any other component in a distributed pub/sub system, will, of course, experience occasional failures. The important thing is how the system manages failures when they do happen. That’s why we’ve designed Ably around the idea of regional & global fault tolerance, which ensures that we can continue to operate even if one or more Ably components fail, without sacrificing quality of service guarantees, exactly-once behaviour included. Whenever Ably ACK’s a published message, the respective message is stored in multiple locations. This way, even in the event of an instance or datacenter failure, we can statistically provide 99.999999 % message availability and survivability.
Unfortunately, under certain conditions, exactly-once semantics may not be possible. For example, while Ably supports long term storage of messages, the default behaviour is to store messages in the system for two minutes, enough time for onwards processing and typical intermittent connections. If a subscribing client attempts to resume message subscription from beyond that two-minute window, it won't be possible. So while exactly-once semantics is desirable, it is no longer possible as the messages are no longer available, in which case the system notifies clients that there has been a failure to resume and the exactly-once promise cannot be upheld. It’s essential for services that offer exactly-once semantics to have these binary behaviours - either a complete success or an indication of a failure so that developers can handle these exceptions appropriately.
Consuming from Ably
There are multiple ways to consume information from Ably, so let’s look at what exactly-once delivery means for each of them.
Consuming via a realtime subscription
Let’s begin by quickly reviewing how a realtime subscription works. We have producers who publish messages to Ably. At the other end, we have consumers who connect to Ably and subscribe to the stream of messages. Note that Ably delivers messages via channels (also known as topics in other pub/sub systems) that any number of consumers can subscribe to.
If, for some reason, a brief disconnection occurs or a client crashes, the connection can be restored or recovered, and the stream of data is resumed precisely where it left off. Let’s see how that’s possible.
Firstly, delivered messages can be placed in persistent storage (for a finite amount of time) rather than delivered in a fire-and-forget fashion. This means that previously delivered messages can be resent or retrieved if needed.
Secondly, each message sent to subscribers has an Ably-assigned serial number. This identifier is persisted on the client-side upon receipt of the message. Once the client reconnects, the serial number is passed on to Ably, so the stream of data can be resumed precisely where it left off.
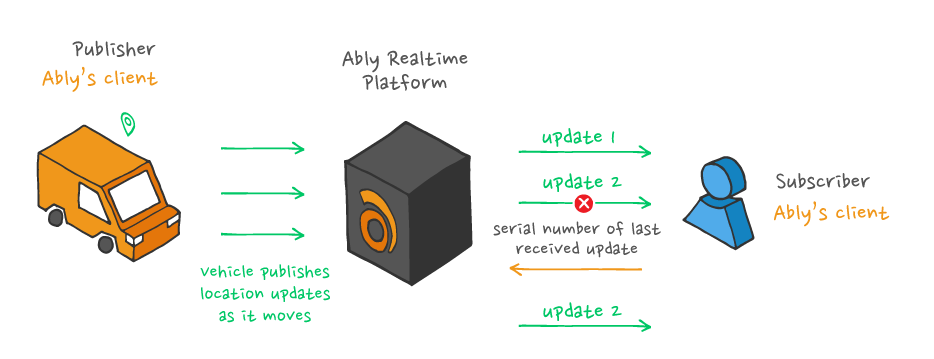
The serial number is based around a timestamp, and it’s used to disambiguate messages that are published in the same millisecond. We’ve primarily designed the serial number to provide ordering guarantees. I say primarily because there is an overlap between exactly-once semantics and message ordering. From an engineering perspective, having ordering simplifies the implementation of exactly-once semantics. When a subscriber reconnects, they only need to send the serial number of the last message they’ve received to Ably. Based on the serial number, which specifies a position in an ordered sequence of messages, we can resume the stream, ensuring that the subscriber doesn’t receive a message twice or none at all. Furthermore, when the stream resumes, the subscriber receives all messages in the right order.
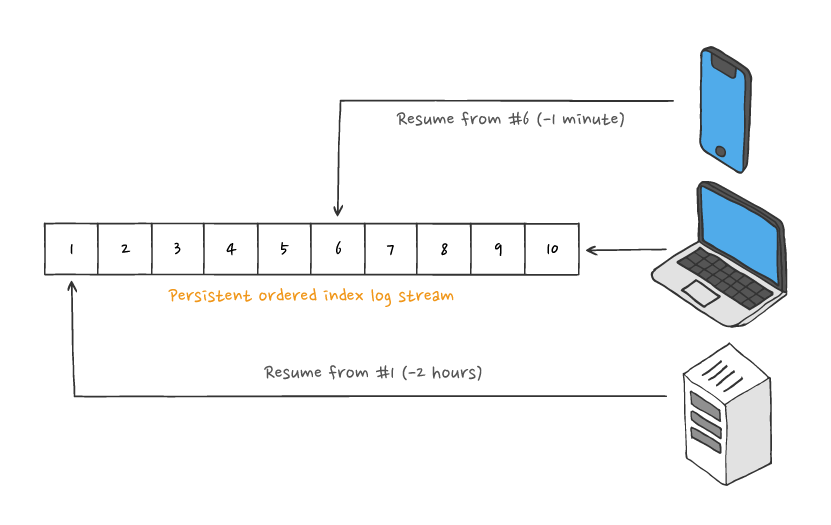
Finally, when disconnections or failures occur, our SDKs provide functionality that allows connection state to be restored. There are two distinct scenarios to mention:
resume- when a connection drops, the Ably client library opaquely attempts reconnection. Once the connection is re-established, the stream resumes, and the backlog of missed messages is sent to the client.recover- specifically for scenarios where a client instance fails and cannot continue, so a new client instance must take its place. It’s necessary to request recover mode in theClientOptionsobject. You also need to provide the previous connection’srecoveryKey, which contains theserialnumber of the last message received.
For a connection to be resumed or recovered, the consumer must be able to atomically process a message and persist the fact that it has processed it (and, implicitly, its serial number). This responsibility is outside of Ably’s control. However, it only involves little and uncomplex engineering effort on the consumer side, and in return, they get a fault-tolerant exactly-once delivery guarantee.
When data is consumed from Ably via a realtime subscription, multiple pull-based (consumer-initiated) protocols can be used. First on the list is our very own realtime protocol. The Ably protocol is built on top of WebSockets and provides a higher set of capabilities and quality of service guarantees, including exactly-once behaviour.
The table below contains more details about all the protocols we support, as well as whether or not they provide exactly-once guarantees:
| Protocol | Exactly-once semantics | Details |
|---|---|---|
| Ably protocol (WebSocket-based) | ✓ | The Ably protocol is built on top of WebSockets to provide additional capabilities and guarantees, including exactly-once delivery. |
| HTTP | ✓ | Ably supports exactly-once delivery over HTTP. |
| MQTT | ✓ | The MQTT protocol has in-built support for exactly-once delivery. |
| SSE | ✓ | SSE supports exactly-once delivery through last event IDs. |
Consuming via integrations with other systems
Another way to consume data from Ably is by configuring integrations that extend our platform into various other systems. This enables Ably to push data to those respective systems in several ways:
- Rule-based event streaming. You can set up rules that react to various events, such as messages being published or channels becoming active. Whenever a relevant event occurs, Ably can send a webhook notification to custom HTTP endpoints, as well as to other services, such as AWS Lambda Functions, IFTTT, or Cloudflare Workers. Learn more about rule-based event streaming.
- Publishing data to streaming or queuing platforms. Data that is published to Ably can be streamed in real time to different streaming and queuing platforms & services, like Amazon Kinesis or RabbitMQ. Learn more about publishing to streaming or queuing platforms.
- Publishing data using message queues. You can also consume data from Ably via traditional message queues that push data to your servers. However, note that most queueing servers don’t support exactly-once semantics. Due to this constraint, with message queues, we can guarantee at-least-once delivery, rather than exactly-once. Learn more about message queues.

When data is consumed from Ably by other systems, exactly-once behaviour is guaranteed as long as the platforms and services that Ably pushes messages to provide an idempotent interface. The table below contains more details about the platforms & services Ably can push data to, as well as the protocols that can be used for this purpose, and whether or not they support exactly-once semantics out of the box:
| Protocol / integration | Exactly-once semantics | Details |
|---|---|---|
| Webhook | X | Ably can send webhook events to Zapier, IFTTT, or your servers. By design, webhooks provide at-least-once guarantees. |
| AMQP | X | AMQP is used for message queues (at-least-once delivery). |
| STOMP | X | STOMP is used for message queues (at-least-once delivery). |
| Serverless platforms | X | Ably can send events that trigger serverless functions on AWS Lambda, Microsoft Azure Functions, Google Cloud Functions, and Cloudflare Workers. In general, serverless platforms only support at-least-once delivery. |
| Apache Kafka | ✓ | Kafka supports exactly-once semantics. |
| Apache Pulsar | ✓ | Pulsar supports exactly-once semantics (effectively-once delivery in Pulsar-specific terminology). |
| Amazon Kinesis | ✓ | Amazon Kinesis provides deduplication capabilities. This means that although a message may be published to Kinesis more than once, in effect, it will only be processed once. |
| Amazon SQS | ✓ | Amazon SQS supports exactly-once semantics via FIFO queues. |
| RabbitMQ | X | RabbitMQ only supports at-least-once delivery (when ACKs are used) and at-most-once semantics (when ACKs aren’t used). |
What exactly-once delivery means for Ably
Here at Ably, we’ve always believed in the importance of designing a distributed realtime pub/sub messaging platform that is easy to use. With that in mind, we believe we’ve managed to design our platform so that it provides exactly-once guarantees with minimum complexity for producers and consumers. Let’s look at a real-life use case to put things into perspective.
HubSpot is a well-known developer of marketing, sales, and customer service software. As part of its offering, HubSpot provides a live chat feature. The organisation is interested in a solution that can power the peer-to-peer chat functionality and stream all that chat data to other services for onward processing and persistent storage. HubSpot has demanding global availability requirements and is very interested in messaging and data integrity guarantees.
HubSpot could have opted to build their proprietary pub/sub system, by using various technologies, including tools such as Apache Kafka, which also provides exactly-once guarantees. However, after some exploration, it quickly became clear that this required far more engineering resources than imagined. To avoid having to deal with hard engineering challenges, HubSpot decided to use Ably as an Internet-facing message broker that enables chat communication between end-users. Furthermore, Ably pushes chat data into Amazon Kinesis, the data processing component of HubSpot’s message bus ecosystem.

By using Ably, complexity for HubSpot is kept to a minimum. The organisation only has to expose an Amazon Kinesis endpoint. Ably powers the peer-to-peer chat and streams said chat data to the HubSpot message bus over as many connections as needed while providing exactly-once and message ordering guarantees.
At Ably, it was our intention from the very beginning to build a distributed pub/sub platform that is well equipped to provide superior performance, integrity, reliability, and availability guarantees - the Four Pillars of Dependability, as we call them.
The exactly-once characteristics of our platform represent an essential component of data integrity. In our case, exactly-once is a guarantee that once acknowledged, a message published to Ably will be delivered to subscribers precisely once, even in the case of brief disconnections or other faults in the system. However, any distributed system will be faced with issues that cannot be prevented or controlled, such as critical failures.
If such an event occurs, the exactly-once guarantee we provide may be impacted. However, this is brought to our customers' attention - Ably automatically sends error messages to notify them. This way, instead of getting silent failures, they can take the appropriate course of action to fix the issue from their end. Hopefully, this highlights a crucial and often overlooked part of exactly-once semantics - knowing when you have those guarantees is as important as knowing when you don’t. After all, data integrity is the end-game, while exactly-once is just a means of achieving it.
Ably & exactly-once semantics: a brief conclusion
Hopefully, this blog post clarifies what exactly-once means in the context of distributed pub/sub systems and helps you understand what exactly-once guarantees Ably provides. As we have seen, exactly-once is a desirable (or even critical) property, as well as a complex engineering challenge. It’s not enough to have one component of your system displaying exactly-once characteristics. That’s because exactly-once is a system-wide guarantee, and you can only claim to provide it as long as all the constituent components of the system play their part in achieving it.
As a distributed pub/sub platform that delivers realtime experiences directly to end-users, Ably is designed to provide superior quality of service guarantees, with exactly-once semantics being a key component of data integrity. Once acknowledged, we guarantee that a message published to Ably is delivered to subscribers precisely once, even in the context of faults in the system and individual components failing. This is possible because Ably was architected to provide regional and global fault tolerance, which ensures message availability and survivability. Furthermore, our SDKs provide capabilities such as idempotent publishing and reconnections with continuity, which guarantee exactly-once behaviour from publisher to subscriber.
If you’re interested in learning more about Ably’s exactly-once behaviour and how our pub/sub platform can help you with your realtime needs, browse the resources listed in the section below and do get in touch.
Further reading
- Four Pillars of Dependability
- The Mysterious Gotcha of gRPC Stream Performance ?
- Balancing act: the current limits of AWS network load balancers
- Engineering dependability and fault tolerance in a distributed system
- What is event streaming?
- Realtime challenges for audience engagement
- Idempotency - Challenges and Solutions Over HTTP
- Idempotent publishing documentation
- Connection state recovery documentation