This article was first published in February 2017, and most recently updated in January 2022 to add new links.
TL;DR: Don’t trust AWS status reports, they’re misleading.
This morning at 1:00am the reporting systems for our Ably realtime platform notified us of a whole range of service failures for one of our customers in a dedicated realtime cluster in AWS’ Northern California datacenter (us-west-1).
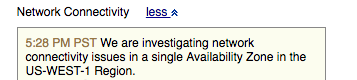
We investigated and discovered network partitioning along with other severe network failures. We checked the AWS status dashboard for information — nothing, all green. 30 minutes later AWS finally posted a status update with this:
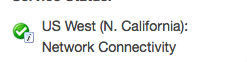
Looking at the notice here is what it said:
Ok, that doesn’t sound too bad, let’s revisit the legend from the AWS status dashboard:

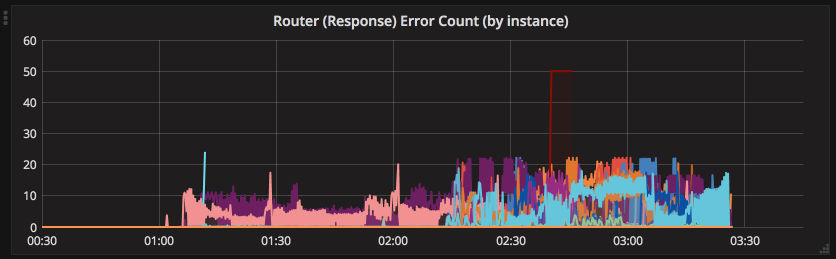
Great, so Amazon is telling us that everything is operating normally and there is a minor notice stating there are Network Connectivity issues. Here is what the cluster looked like:
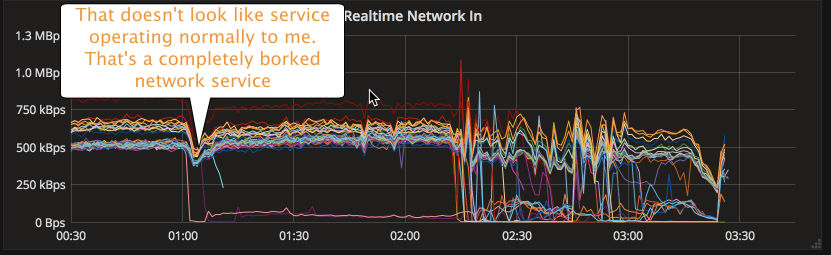
And here is the net effect for that customer’s dedicated datacenter:
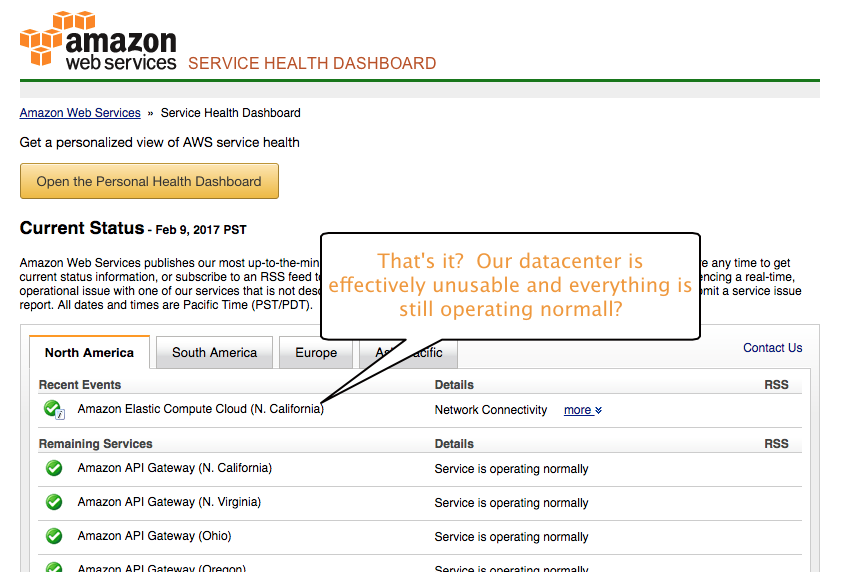
So we contacted our customer about the issue and discussed the options (we ended up setting up a new cluster for them in another region). However he visits the AWS status page and doubts our “truth” because quite rightly, he says everything is green. Here is what the status page looked like:
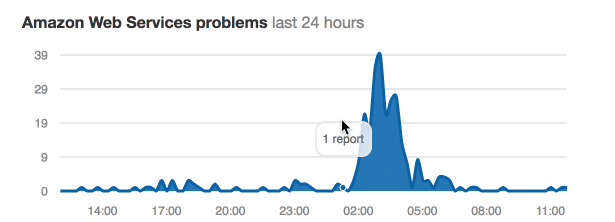
Right, so we doubted ourselves and considered that maybe this is just us. Looking at downdetector.com though that was clearly not the case:
Ok, so at this point we now knew that:
- Amazon AWS flat out lies — considering a cloud based network accessible service to be “operating normally” when the network is not working is insane
- We cannot trust Amazon AWS status updates because the information provided to us about the severity of the issue or how quickly it will really be resolved
We suspect if we had reached out to AWS in this post-truth world, this is what we would have got:

So what should have happened
Fortunately that’s pretty simple — what we require is honesty and we expect AWS to err on the side of caution.
Here’s what we did at Ably for our customers to notify them about what happened when we detected the fault:
- We had monitoring systems to tell us immediately there was a fault, which in turn created an incident automatically in our status site within minutes of the problems in us-west-1.
- We then manually updated the incident on our status site with our commentary and emailed everyone signed up for status updates with the issue and what we were doing about it (which was to route traffic away from the faulty datacenter).
- We took an honest approach and weren’t worried to show a bit of orange on our status site. Because if something is not operating as expected, then we are pretty sure that is not classified as “operating normally” and at best should be classified as “performance issues”. See our status dashboard below:
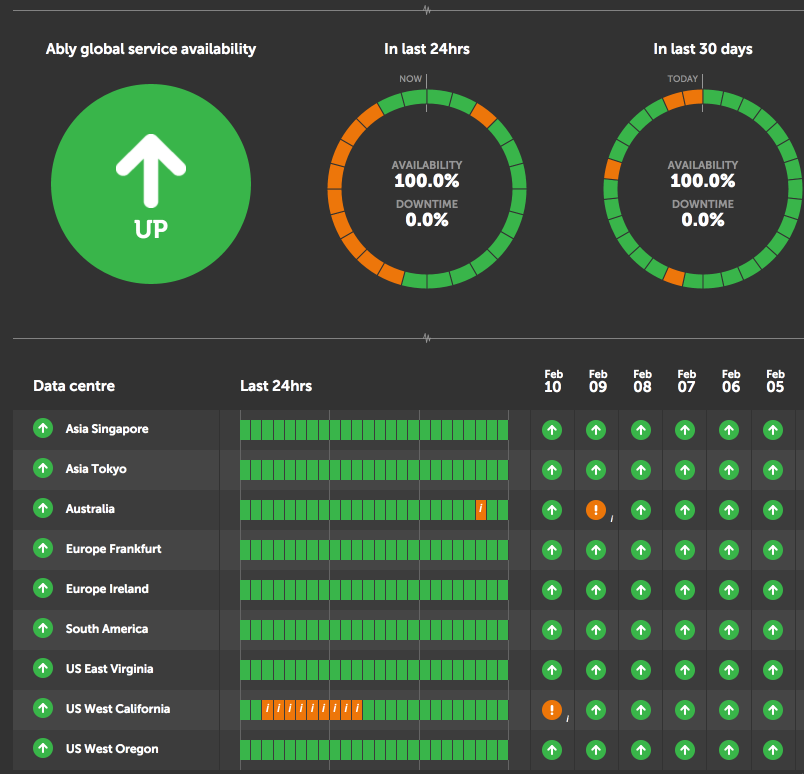
- We updated our customers once this issue was resolved via email and on our status site.
- We kept a record of what happened for customers to review in our incidents section.
Amazon AWS — you can and “should” do better
Our plea to Amazon AWS is please don’t fall into this post-truth trap and aim to have false green in your status dashboard. Looking at your AWS status dashboard today, in spite of the fact that an entire datacenter was unusable for a few hours this morning, is completely green. There is so much green on the status page that we were unable to fit the screenshot in one image (max height of 30,000 pixel). Amazon, your AWS status page today has 38,000 vertical pixels of green!
We rely on AWS infrastructure to deliver our realtime data delivery platform. Amazon needs to take their downtime and issues more seriously, be more upfront about what’s going on, and not wait half an hour to report that a datacenter being offline is “operating normally”. It’s not like they don’t have resources that outstrip any other infrastructure provider, they’re hiring 100k employees in the next 18 months.
Amazon AWS, we expect more of you. Please be honest.
Latest from Ably Engineering
- Channel global decoupling for region discovery ?
- Conform and monitor with our GitHub repo audit tool
- Save your engineers' sleep: best practices for on-call processes
- Squid game: how we load-tested Ably’s Control API
- No, we don't use Kubernetes
- Balancing act: the current limits of AWS network load balancers